空间记忆:智能系统缺失的认知底座
Lu Liu/刘露,张彦峰
目录
- Chat memory ≠ Spatial memory
- 从认知地图(cognitive map)到工程系统
- 从感知突破到认知困境
- 空间智能的三层架构:感知(Perception) / 认知(Cognition) / 记忆(Memory)
- 技术路线、主流方法与评测
- 我们的判断与阶段性进展
- 从洞穴到世界
- 参考文献与延伸阅读
TL;DR:大模型已经很擅长处理“词语世界”:能写、能说、能画、能编程,也能调用工具、执行流程。但一旦问题落到物理世界,一个基础短板便会显现:系统缺少一种长期、可查询、可校准、可追溯的时空状态记忆。它不仅要知道一个物体“现在看起来在哪里”,还要能维护它的身份、位置、关系、变化历史、证据来源与置信度。没有这层能力,再强的感知也难以支撑稳定的规划、纠错与持续学习。本文所说的 空间记忆(Spatial Memory),正是面向物理世界的这层认知底座。
这篇文章围绕一个核心判断展开:
空间记忆不是对话记忆的扩展,也不是视频存储或向量检索的升级,而是智能系统进入物理世界时必须补上的时空状态维护层。
这是一个宏大的主题。通过有限的篇幅,我们希望阐明这几件事:空间记忆有长期的认知科学与神经科学根基;当前基础模型在空间推理、跨视角一致性、主动探索与长期状态维护上仍明显低于人类水平;具身智能、自动驾驶和 XR 正从不同应用方向把它推到前台;从系统架构看,空间智能可以抽象为“感知—认知—记忆”三层;而真正可用的空间记忆必须结构化、紧凑、自洽、可校准、可解释,并能在证据不足时诚实表达不确定性。
1. Chat memory ≠ Spatial memory
今天的 AI 系统 已经能在“文本世界”里高效工作:生成、检索、写代码、调用工具,很多能力都在逼近生产可用。以浏览器、桌面和移动设备操控型 Agent 为代表的系统,也开始把这种能力延伸到更复杂的数字环境中。然而,一旦任务真正指向 物理世界,同样强大的系统就会掉链子:它可以在单帧图像中正确指出“桌上有一串钥匙”,却未必能在十分钟后判断那串钥匙是被人拿走了、被抽屉遮住了,还是被另一个相似物体混淆了;它可以在视频片段里描述“杯子在桌子左侧”,却未必能在第二天重定位时判断:究竟是桌子移动了、坐标系漂了,还是房间布局真的发生了变化。
这并非某一款模型的偶尔失误。自 2022 年 11 月以来,我们持续观察和评估大模型在不同尺度、不同类型空间认知任务上的表现,得到的是相近结论 [21]。来自其他同行的独立研究也给出了相似的评估结果 [12, 15, 17, 18]:一旦任务要求系统持续理解“物体在哪里、后来发生了什么、我为什么相信这个判断”,这块短板就会暴露。更麻烦的是,系统往往不会诚实地说“不知道”,而是非常自信地给出错误答案。
这其实并不奇怪。缺少可追溯的空间状态,系统自然无法回答那些对人类而言稀松平常、但对 AI 而言必须依赖时空锚定和持续记忆的问题:
- last-seen(最后一次见到):我的护照/钥匙上次出现在哪个位置?大约是什么时间?证据是什么?
- containment(容器/隐藏状态):我把螺丝刀放进抽屉之后,它“现在”仍在抽屉里吗?系统有多确定?何时需要再确认?
- change(变化检测):从昨晚到现在,玄关区域有哪些对象新增、消失或移动?移动了多远?
- state audit(状态核查):我出门时炉灶关了吗?窗户是否处于关闭状态?
这些问题共享同一种结构:具体对象、空间位置与关系、时间维度、证据来源,以及随时间变化的不确定性。此外,尺度也会改变这些概念的含义:房间里的钥匙、道路上的车辆、城市中的拥堵模式、全球尺度的气候过程,都是时空状态问题,但对象粒度、时间跨度和不确定性的描述方式与研究方法完全不同。本文后面还会回到这个多尺度挑战,用多长的“尺”和多细的“刻度”去描摹研究对象,是需要仔细思量的。在开篇处,只需要先抓住一点:物理世界中的记忆天然是空间性的,也是时间性的。
因此,最近 Agent 领域讨论的“记忆”不能简单覆盖这里的问题。我们至少要区分两类本质不同的记忆:
- Chat memory(对话记忆):对话历史、用户偏好、任务上下文等,主要服务语言交互。
- Spatial memory(空间记忆):对象、地点、关系、事件、证据与不确定性,主要服务物理世界中的状态维护与行动决策。
这两类记忆的结构不同。对话记忆通常是线性的、语言性的、以会话和用户偏好为中心;空间记忆则必须是时空锚定的、对象中心的、可随感知更新的,并且要能处理遮挡、漂移、相似物体、负观测和置信度衰减。换句话说,空间记忆需要在系统架构中专门建立一个可持续维护的物理环境状态层,而不能通过拉长聊天记录或给文本加位置坐标来替代。
因此,本文后续主要使用 空间记忆(Spatial Memory) 这个术语(据上下文决定中英文形式,含义相同)。它不等同于“把监控视频都存起来”或“给照片做向量数据库”这类存储方案;真正要建立的是系统与物理空间交互时所必需的一种基础能力:
长期维护、可查询、可解释、可度量的世界状态。

2. 从认知地图(cognitive map)到工程系统
空间记忆并不是大模型时代才出现的新概念。它有一条清晰的百年线索:认知科学关心生物如何把连续经历组织成可用于导航、规划和泛化的内部表征;神经科学关心这种表征在大脑中如何实现;工程系统则关心如何把这种能力做成可运行、可更新、可查询的系统 [67, 68]。
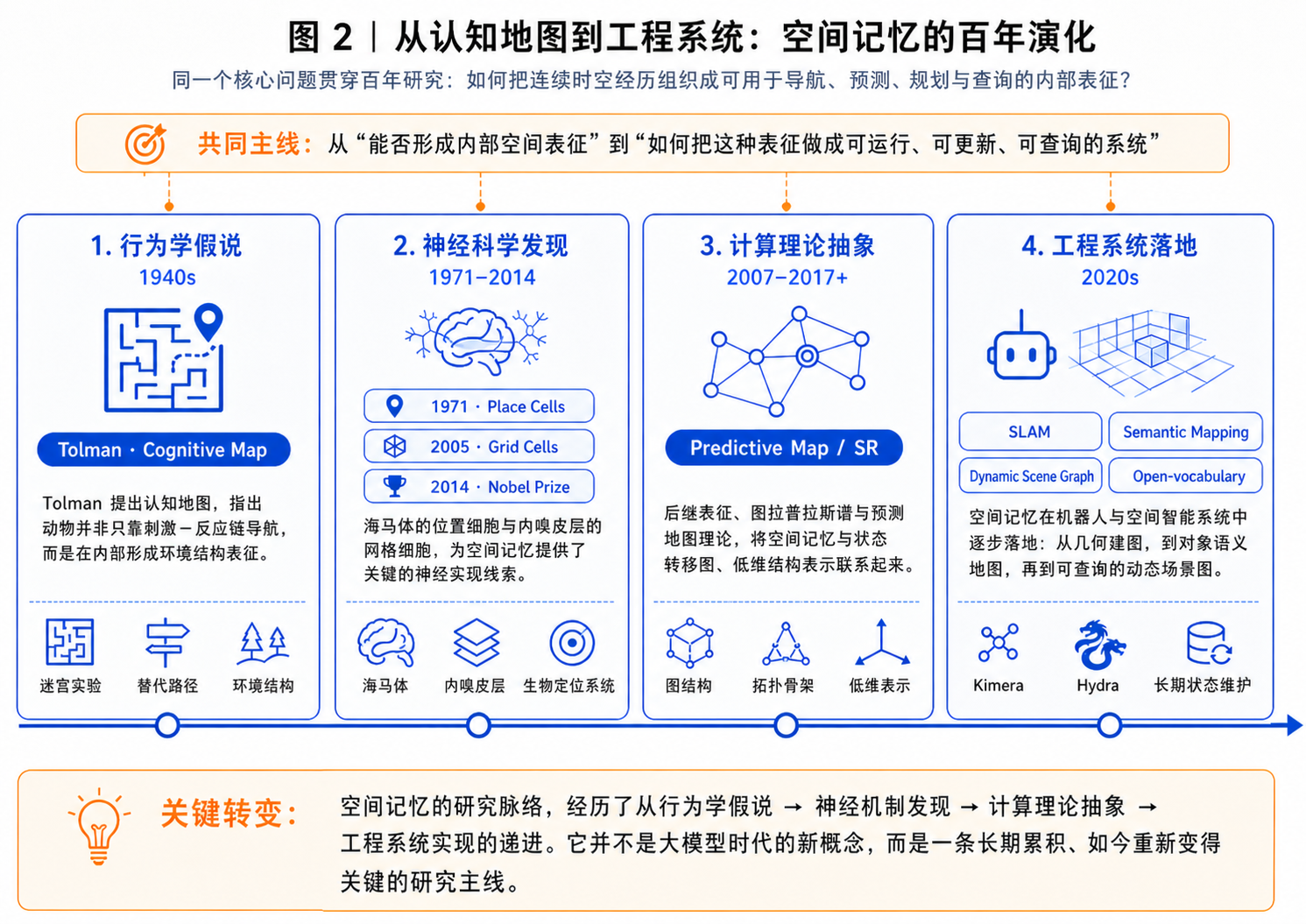
如果快速梳理,可以看到几个经典节点。
第一,Tolman 与认知地图。 早期行为主义者倾向于把动物导航理解为“刺激—反应”的动作链:看到某个线索,就执行某个转向。但 Tolman 的迷宫实验表明,老鼠并不只是记住一串动作,而是在内部形成了某种环境结构。当路线被阻断时,它们仍能选择替代路径,这意味着内部表征中包含“哪些地方彼此连接”“哪条路线更短”这类关系信息。Tolman 称之为 cognitive map(认知地图),这是空间记忆研究中最重要的概念起点之一 [3]。如果说 Tolman 提供了行为学层面的内部表征假说,Hebb 的 cell assembly 与 phase sequence 理论则提供了早期神经机制想象:连续经历可以被神经元集群与序列化活动组织起来 [69]。
第二,place cells 与 grid cells。 O’Keefe & Dostrovsky 在海马体中发现了位置细胞(place cells)[4],Hafting 等人在内嗅皮层发现了网格细胞(grid cells)[5]。前者像是在特定位置被激活的“地点单元”,后者则以近似周期性的方式为环境提供拓扑保留的度量骨架。它们共同说明:空间记忆不是抽象隐喻,而有明确的神经实现线索。2014 年诺贝尔生理学或医学奖授予 O’Keefe 以及 Moser 夫妇,也标志着这条线索成为现代神经科学的核心成果之一 [6]。
第三,从神经编码到图谱表示。 Stachenfeld 等人的 predictive map 理论进一步把空间记忆与图方法连接起来:如果把环境表示为状态转移图,后继表征(Successor Representation, SR)的低维特征模式与图拉普拉斯谱基密切相关 [70, 71, 72]。这给工程系统一个重要启发:空间记忆未必需要保存稠密、笨重的几何细节,而可以优先保存环境拓扑和关系结构的低维骨架。换句话说,生物系统也许并不是在“存一张高清地图”,而是在维护一个可用于导航和预测的结构化压缩表示。
还有个很有意思的点值得一提:空间认知并非哺乳动物或灵长类独有。在脊椎动物内部,海马形成及其同源结构反复承担地图式、关系式空间记忆;而在无脊椎动物中,它们虽然没有海马体,也缺乏在解剖形态上与脊椎动物同源的 Pallium(披盖或皮层结构),却展现出极其精密的空间导航能力。沙漠蚂蚁能通过路径积分计算回巢方向,蜜蜂能记忆地标序列并在熟悉地形中高效觅食。支撑这些能力的是中央复合体(central complex)和蘑菇体(mushroom body):前者负责朝向表征、路径积分与目标方向比较,后者负责视觉场景记忆与地标识别。
这组证据之所以重要,是因为它说明空间记忆不是语言智能的副产品,也不是人类高级文化活动的附属能力。它更像是一种在不同神经架构中反复演化出来的基础生存计算。跨物种真正保守的不是某一块具体解剖结构,而是一组核心空间计算能力:朝向表示、自运动积分、地标/场景记忆、参考系转换,以及目标比较与转向决策。
在这个基础上,认知科学和神经科学逐渐形成了几条共识。第一,空间记忆不是坐标列表,而更像由地标、路线和拓扑关系组织起来的图结构。第二,它天然具有多尺度层级:从具体路线,到房间/区域,再到建筑或城市级结构。第三,空间记忆不是一次经历后就静态固化的东西,而会通过回放、巩固和再组织逐步变成更稳定的长期表征 [7, 8]。
这些科学发现持续影响工程系统设计。“空间记忆”以不同名字、不同形态在各个学科方向中开枝散叶:SLAM 提供几何和定位基础;对象级语义地图让地图可被人类语言查询;动态场景图开始表达对象、区域、关系和时间变化;开放词汇方法则增强了系统面对未知对象时的灵活性。Kimera 和 Hydra 等动态场景图系统已经很接近空间记忆的“关系表达”要求 [9, 10],但在长期不确定性建模、证据链追溯和跨会话状态维护方面仍然不够完整。
所以,空间记忆的研究并不是凭空冒出来的。它背后有认知地图的理论根基、有海马—内嗅系统和昆虫导航的生物学证据,也有 SLAM、语义地图、动态场景图等工程传统。本文的任务不是重新发明这个概念,而是指出:当 AI 系统开始进入真实物理世界时,这条长期存在,却又被忽视的研究线索正在变成一个新的系统瓶颈。或许,“被忽视”恰恰是因为这种能力对于我们普通人来说太基础,太平常了吧。
3. 从感知突破到认知困境
3.1 感知 ≠ 认知
从深度神经网络到多模态大模型,AI 在“看见”和“描述”层面已经取得了惊人的进展。它们能识别复杂图像、理解视频片段、生成逼真画面,也能用自然语言描述几乎任意场景。从表面上看,这似乎是在朝“空间智能”直线前进。
如果借用《快思考,慢思考》中被广泛传播的系统 1 / 系统 2 区分 [81],这种误读并不难理解:感知更接近快速、自动、模式驱动的处理;而空间认知往往涉及慢变量——对象身份、关系结构、历史状态、证据校验、反事实判断与行动计划。这个类比当然不能直接等同于机器架构,但它提醒我们:把“认知”完全吞进“感知”,很容易把短时模式识别误认为是长期世界理解。
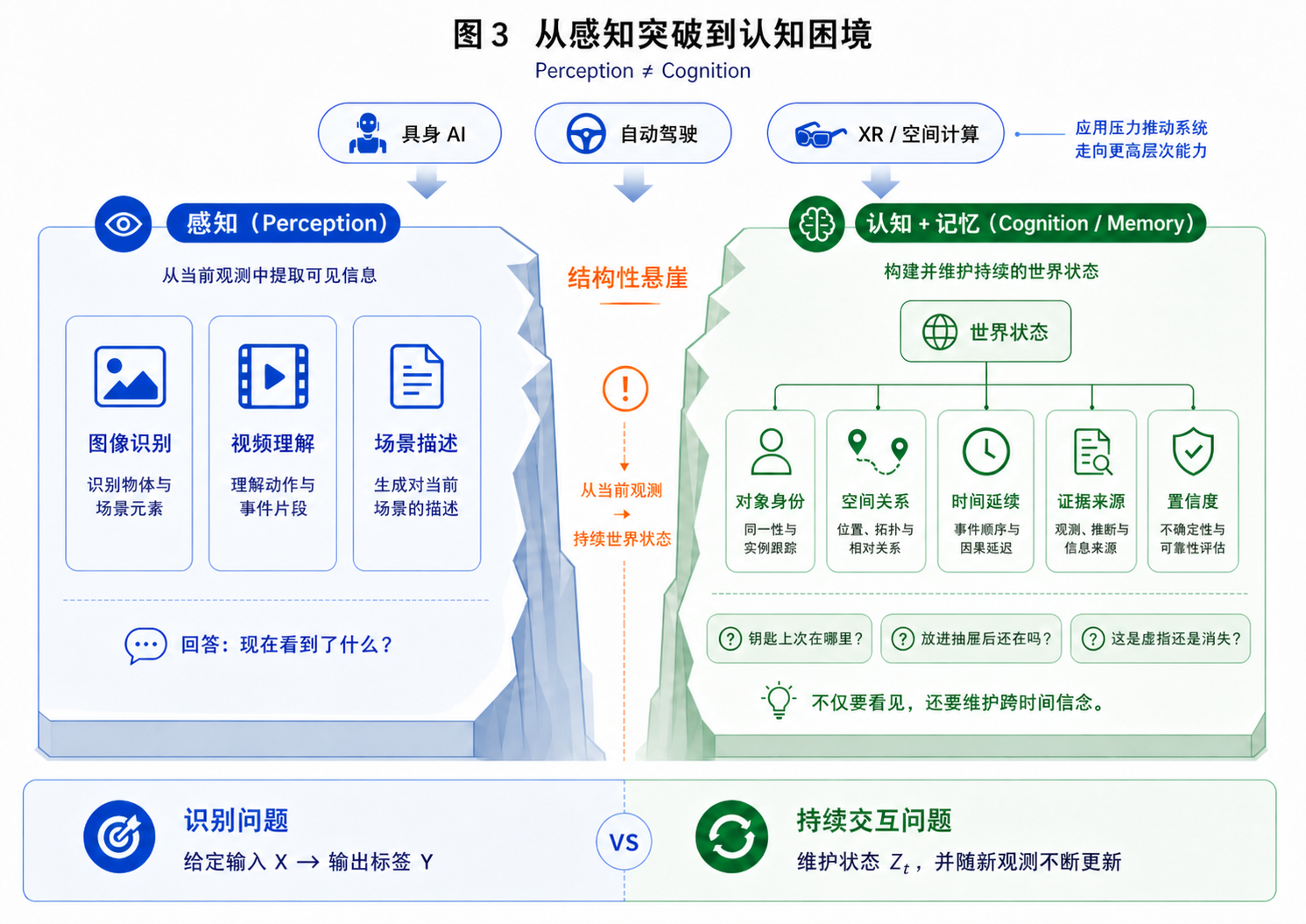
越来越多的评测表明,感知能力的提升并不会自动转化为空间认知能力。VSI-Bench 等空间推理基准显示,当前视觉语言模型在构型推理、度量估计、跨视角一致性和时空关系问题上仍明显低于人类水平 [12];Khangaonkar et al. 的空间不一致性实验也表明,模型很难稳定判断两张不同视角照片中哪些物体违反了基本三维一致性 [58]。这类失败不能简单归因于“没看清”。更深的问题在于:模型没有形成可持续更新、可用于推理的三维世界状态。
这背后有两个结构性原因。第一,空间位置、形状、方向、遮挡和拓扑关系本来就是高度结构化的信息,未必适合完全被压进不可解释的高维隐空间中。Cog3DMap、Map2Thought 等近期工作从不同角度传递了同一个信号:当显式三维结构或度量认知地图被提供给模型时,空间推理能力会得到改善 [60, 61]。第二,感知指标与空间推理指标并不天然同步。识别准确率、深度估计、视频一致性可以持续进步,但这并不等价于系统已经学会维护对象身份、关系、历史状态和不确定性。
让我们以一个家庭机器人例子来说明其中的差异。感知系统可以识别“钥匙在桌上”,但当用户问“我的钥匙现在在哪?”时,系统需要回答一串跨时间问题:这是哪把钥匙?什么时候看到的?后来有没有被移动?如果现在看不到,是因为遮挡、视角限制,还是钥匙真的不在了?答案还必须附带证据和置信度。前者是 perception,后者才是 cognition 与 memory 的协同。
这就是本文反复强调的区别:感知处理当前输入,认知组织世界结构,记忆维护跨时间信念。 三者相关,但不能互相替代。
3.2 三股应用压力的同向汇合
为什么这个问题在 2024–2026 年变得特别突出?一个重要原因是,多个应用方向几乎同时从“看懂当前场景”推进到“持续进入物理世界”。其中最典型的三条线,是具身智能、自动驾驶和 XR。它们表面上看起来不同甚至毫不相关,底层却都在逼迫系统回答同一个问题:当世界持续变化、观测并不完整时,系统如何维护一个可更新、可校准、可追溯的状态?
3.2.1 具身智能:长时任务使记忆成为必需品
具身智能首先暴露了这个问题。一个机器人如果只依赖当前帧或过去几秒的上下文,很难完成跨房间、跨步骤、跨时间的任务;也很难稳定复用之前的探索经验,来解释“为什么刚才的计划失败了”。近期,DAAAM、Mind Palace 等工作把问题从单帧识别推向跨时间描述、长时主动问答和结构化场景记忆 [13, 49];MemoryVLA、RoboMemory 等工作则从操控和多记忆系统角度说明,显式记忆模块可以显著改善长程依赖任务 [48, 53]。
这两年,一些新的基准测试也在往同一方向推进。S3-Bench 将空间问答置于流式设定下,查询被锚定到特定时间戳,只能使用截至该时刻的观测来回答 [39];EMemBench 则从智能体自身轨迹中生成情景记忆问题,发现空间推理在视觉设定中仍是持续瓶颈 [41]。这些工作共同说明:具身智能需要的不仅是更大的上下文窗口,更是结构化、有分工、可主动更新的记忆子系统。感知告诉机器人“现在看到了什么”,空间记忆则帮助它判断“现在相对于过去意味着什么”。
3.2.2 自动驾驶:从实时状态到道路经验记忆
自动驾驶把同一个问题推到了更高速度、更高风险的场景中。车辆、行人、骑行者和静态障碍物都在持续变化;遮挡、传感器噪声、地图过时和多主体博弈随时发生。系统不仅要检测当前帧中的目标,还要维护它们的身份、轨迹、速度、意图和不确定性:一辆车被货车短暂遮挡,并不意味着它从世界中消失;一个行人被路边车辆挡住,也不意味着风险解除。
因此,自动驾驶中的空间记忆首先表现为局部动态状态维护:哪些对象仍然存在,哪些对象只是暂时不可见,哪些变化可信,哪些不确定性必须进入预测与规划。3D occupancy、BEV 表征、4D occupancy forecasting、driving world model 等方向的兴起,本质上都在尝试把道路环境表示为一个随时间演化、可预测、可规划的时空状态场 [74, 75]。
但自动驾驶还揭示了空间记忆的另一层含义:驾驶经验的长期积累。一个熟练司机并不只根据当前传感器输入驾驶,还会记住某些地点在某些时段的“惯常模式”:这条车道下午经常被右转车辆堵住,那个路口行人会突然从遮挡后出现,某段匝道合流总是比地图规则更激进。对自动驾驶系统而言,这类经验可以来自大量车辆在长时间跨度上的轨迹、干预、风险事件和通行效率数据。它们共同形成一种车队级的、地点与时段绑定的“道路空间记忆”。
注意到这点的显然并不只有我们。Lanelet2 强调高精地图可以把 previous journeys 中获得的知识迁移到当前驾驶中,补偿传感器看不到或暂时不可靠的部分 [76];Mobileye REM 以众包方式持续更新道路语义、交通规则与 driving culture [77];fleet learning 架构和 nuPlan 等真实驾驶日志基准,则进一步说明自动驾驶正在从大规模车队经验中学习规划和预测策略 [78, 79]。比如在某些特定路段,某条车道经常因为大量转弯等待而变慢;如果系统拥有这种长期道路经验,就可以提前变道,而不是到瓶颈前才被动反应。
这说明,自动驾驶所需要的空间记忆不只是“眼前有哪些物体”,还包括“这个地点长期以来通常会发生什么”。它把空间记忆从单车实时状态维护,进一步推向车队级、长周期、可追溯的集体经验。
3.2.3 XR / 空间计算:从静态锚点到变化追踪
XR 则让空间记忆变成普通用户也能感受到的问题。虚拟窗口、空间小组件或共享标注一旦被放在真实房间中,系统就必须在下一次佩戴、下一台设备、下一个用户进入时恢复同一空间状态。Apple Vision Pro 的空间锚点、visionOS 中的空间小组件,以及 Meta Quest 的 Scene Understanding API 和 Spatial Anchors SDK,都在不同层面推动“虚拟内容跨会话稳定存在”这一能力。
但空间锚点只是第一步。真正困难的是变化追踪:用户第二天回到同一个房间,系统需要能够判断这还是同一个空间;家具移动了,系统要区分“物理世界改变了”还是“我的坐标系漂了”;多个用户协作时,系统还需要同步他们对同一空间的状态理解。这里的核心是一个共同维护、可同步、可更新的空间状态后端。
因此,XR 把空间记忆从后台工程问题变成了产品体验问题:如果虚拟对象不能稳定回到原位,如果系统不能理解真实空间的变化,所谓“混合现实”就只能停留在一次性的视觉效果,而难以成为持续可用的空间计算平台。
3.3 感知与认知带宽之间的“亿”点差距
三股应用压力背后,有一个更一般的计算神经学原理:感知可以是高带宽的,但行动和推理必须依赖低维、结构化、可更新的内部状态。Zheng 与 Meister 对人类认知吞吐量的估算很有启发性:感官输入可近似达到 10⁹ bits/s,而行为与认知层面的有效吞吐量只有约 10 bits/s (注意这是信息论中的香农比特,不是计算机存储中的二进制比特),二者之间有一亿倍的差距 [11]。这个数字不必被机械套用到机器系统上,但它提醒我们:智能的关键不在于保存所有输入,而在于把高维观测 “sift(压缩/筛选)” 成少量可用于认知决策的状态变量。
当任务从“识别”转向“持续交互”时,问题类型也随之改变。识别问题可以写成给定输入 X 输出标签 Y;持续交互则要求维护一个随时间演化的内部状态 Z,根据新观测和历史约束不断更新,再基于 Z 回答查询或选择行动。这已经接近动态系统和信念更新问题,而不是更大的分类器可以自然解决的问题。
这也是为什么具身智能、自动驾驶和 XR 会在同一时期撞上类似瓶颈:它们都要求系统从“处理当前帧”走向“维护世界状态”。接下来的问题就是:这样的状态层应该放在系统架构的什么位置,它又应该如何被表示、更新和查询?
4. 空间智能的三层架构:感知(Perception) / 认知(Cognition) / 记忆(Memory)
前面几节讨论的是“为什么需要空间记忆”,而且也把“认知”这个小巧的决策处理中枢从“感知”中择了出来。接下来要回答的是另一个问题:如果一个智能系统真的要进入物理世界,空间记忆应当位于系统架构的什么位置?
我们的看法是,空间智能不适合被压缩成一个单一的“视觉模型”,而应被理解为三层协作结构:
- Spatial perception(空间感知):把传感器信号转化为观测,例如对象、边界、深度、语义、运动线索和局部几何。
- Spatial cognition(空间认知):把零散观测压缩为可用于行动的内部空间模型,例如地标、路线、区域、拓扑关系、约束和可操作状态。
- Spatial memory(空间记忆):把这个内部模型跨时间稳定下来,使其可更新、可查询、可校准,并保留证据、不确定性与状态变化历史。
这里还需要避免一个常见误解:视觉不是感知的全部,更不是空间智能的全部。蝙蝠依赖回声定位,昆虫依赖路径积分和地标记忆,许多弱视觉动物仍能稳定导航。空间智能的核心不在某一种传感器,而在于能否把多模态输入组织成可行动、可更新的内部空间模型。
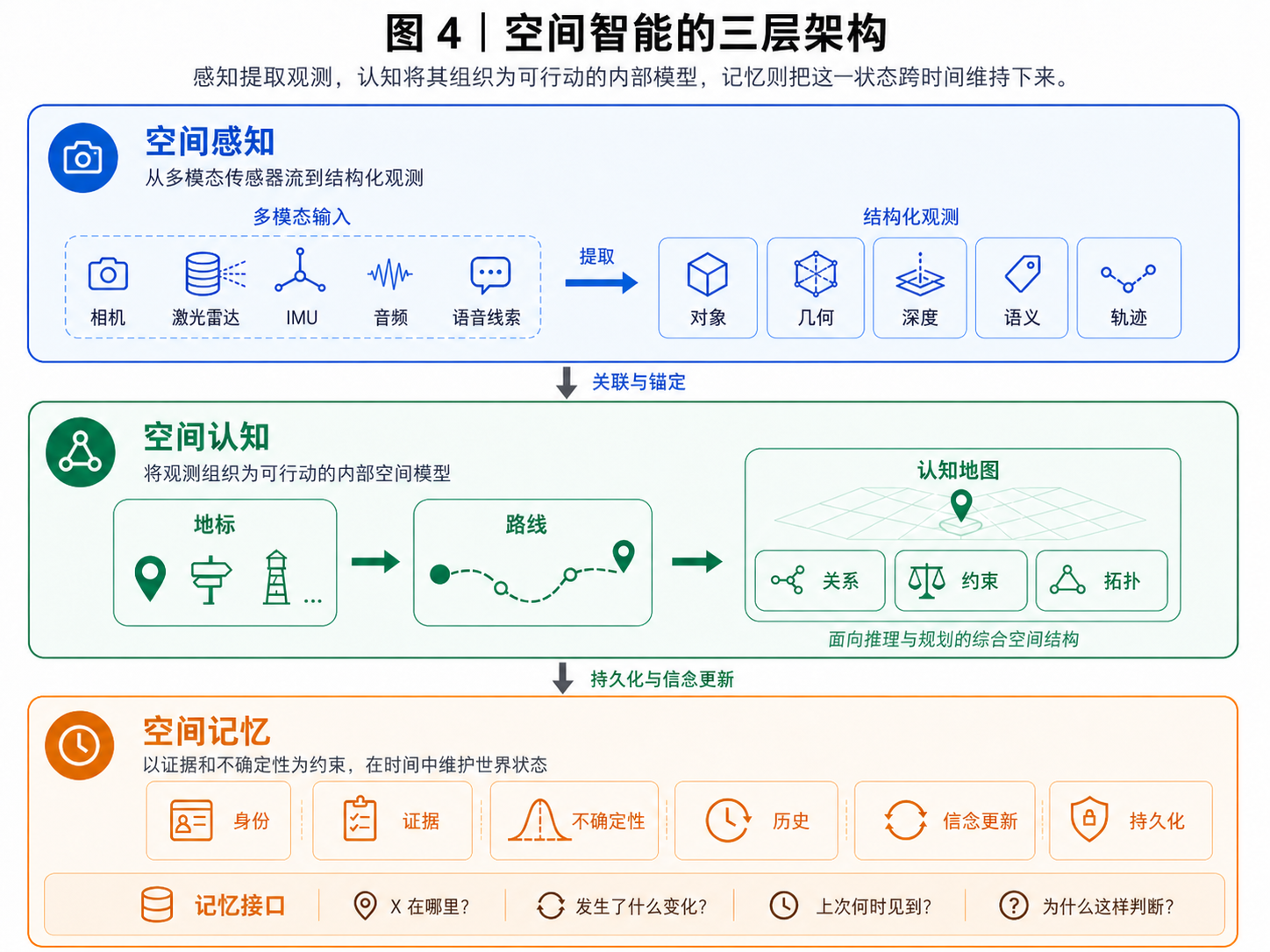
一句话概括:空间记忆是感知与行动之间的状态维护层;它把长期的、时空锚定的观测组织成可跨时间更新、可查询、可校准、可解释的世界状态,而不只是感知模型的缓存。
4.1 三层架构:从观测到状态,再到跨时间信念
这三层的区别,不在于它们使用哪一种模型,而在于它们处理的问题类型不同。
感知层处理的是当前输入。 它回答“现在看到了什么”:这里有一把钥匙、一个抽屉、一堵墙、一辆车、一个行人,或者一段可通行空间。它可以非常强大,也可以是开放词汇的,但它本质上仍然面向当下观测。
认知层处理的是结构。 它回答“这些观测之间如何组织成一个可行动的空间”:钥匙在桌上,桌子在房间里,门连接两个区域,某条车道即将汇入主路,某个地标可用于重定位。认知层的关键在于把高维感知压缩成少量可组合、可推理、可用于行动的变量和有逻辑的关系,而不是保存更多像素。
记忆层处理的是信念。 它回答“这个状态在时间中如何延续”:钥匙十分钟前在桌上,现在是否仍可信?抽屉关上后,看不到钥匙是否意味着钥匙不存在?车辆被遮挡后,是否仍应进入预测?房间重新扫描后,变化来自物体移动还是定位漂移?记忆层的核心任务,是在新观测、旧证据和不确定性之间持续校准,而不只是简单存储历史。
这个分工解释了为什么“更强的视觉模型”不能自然替代空间记忆。视觉模型可以把当前帧看得很清楚,但只要系统需要跨时间回答 last-seen、change、containment、state audit 这类问题,就必须有一个独立的状态维护机制。
这个三层架构本身并不复杂,也不需要被解释成某种严格的神经科学对应物。它首先是一个工程分工:感知负责提出观测,认知负责组织结构,记忆负责维护跨时间信念。真正值得展开的,是我们为什么认为这样的分工合理。下面两小节分别给出两类背景:一类来自认知科学中空间表征的层级化组织,另一类来自长期系统运行时必须遵守的简约性与自洽性约束。
4.2 认知科学的启发:从地标、路线到可操作的空间结构
认知科学中的“地标 → 路线 → 认知地图”递进,并不是“感知—认知—记忆”三层架构的严格同构。它更像是一个重要提醒:空间智能不是从像素直接跳到全局推理,中间必须有逐层组织的空间表示。换句话说,三层工程架构不是从这套认知科学框架中机械推导出来的;后者提供的是经验骨架和设计启发。
地标(landmark) 是局部、可识别、可再次定位的空间锚点。它可以来自视觉,也可以来自声音、触觉、气味或几何结构。对人工系统来说,地标不一定是传统意义上的“建筑物”或“路标”,也可以是一个稳定角点、一组房间布局特征、一段车道拓扑,或者一个反复出现的对象配置。
路线(route) 把地标组织成可执行的序列:从 A 到 B,再到 C;看到某个门之后左转;沿着走廊经过两个开口;在某个路段提前变道。路线表示比单个地标更复杂,因为它引入了方向、顺序、动作和局部目标。
认知地图(cognitive map) 则进一步把多条路线整合成关系结构。它不只是“走过的路径列表”,而是支持“哪里彼此相邻”“哪条路更短”“如果这里被阻断,可以从哪里绕行”这类推理。如果直白地说,当一个人自信地说“那个地方我熟”的时候,通常就表示他的脑海中已经构建起了关于那个地方的认知地图。
Tolman 的迷宫实验、place cells 与 grid cells 的发现,以及后来的 predictive map 理论,都从不同角度支持了这种层级化理解 [3, 4, 5, 70]。近年的 AI 空间认知评测也在复用类似的能力拆分,把地标识别、路径整合、布局理解、视角切换等维度单独拿出来测量,结果显示当前模型在不同维度上存在明显不均衡 [23]。这说明“空间智能”内部并不是一个平滑统一的能力块,而是一组需要被逐层组织和逐层检验的能力。
从计算性质看,地标、路线与认知地图的复杂度也在递增:地标识别主要是局部匹配,路线表示需要组织序列,认知地图则涉及跨路径、跨区域的关系整合与推理。因此,AI 系统也不应该从感知输出直接跳到全局查询。中间必须有某种结构化的空间表示,把“看到了什么”转化为“世界如何组织”。BSC-Nav、ESWM、Hippoformer 等工作从不同方向尝试把脑启发的空间表征翻译成工程系统,也说明这条路径已经不只是概念类比,而正在变成可实现的架构探索 [57, 59, 62]。
这里还可以重新理解 §2 中提到的 SR / GFT / grid-cell-like patterns 之间的关系。它们提示我们:认知地图未必需要保存稠密坐标,而可以保存环境结构的低维谱骨架。换句话说,好的空间表示应该优先保留对导航、预测和查询有用的低维结构,而不是把所有局部细节都堆进记忆。
4.3 两条设计纪律:简约性与自洽性
无论从信息论、认知科学还是工程系统看,一个长期运行的空间记忆系统都应该满足两个约束:简约性(parsimony) 与 自洽性(self-consistency)。这与马毅教授团队在《深度表征学习的原理与实践:记忆的数学理论》中强调的理论主线相呼应:智能系统需要从高维观测中学习低维、紧凑、结构化的表征,而这种表征可以被理解为从外部世界数据中学得的可计算记忆或经验知识 [82]。
本文并不把这套表征学习理论直接等同于空间记忆架构。它更重要的价值,是把“记忆”从一个经验性比喻推进为一个可以被数学化讨论的表征问题:什么应该被压缩,压缩后是否仍保留可用于预测和行动的结构;系统如何在新观测到来时校验、修正并保持自身状态一致。放到空间记忆语境中,这两点分别对应两条工程纪律:认知层要简约,记忆层要自洽。
简约性约束认知层如何压缩世界。 空间记忆不应默认保存所有视频帧、所有点云、所有中间特征,然后在查询时做暴力检索。那样不仅存储成本高、查询成本高,也会带来严重隐私风险。更合理的做法,是把感知输出压缩为对象身份、空间关系、时间戳、置信度、证据指针和必要的局部几何等结构化表征。也就是说,系统应该尽量保存“可用于推理和行动的状态”,而不是保存“看起来像完整世界的原始数据”。如果说感知层产生的是高带宽观测流,那么认知层的任务就是把它们筛成少量稳定、可组合、可操作的状态变量。
自洽性约束记忆层如何更新世界。 真实环境中的观测并不是绝对真理:光照会变化,物体会遮挡,定位会漂移,相似物体会混淆,传感器也会漏检。一个长期运行的系统不能每来一帧就完全覆盖旧状态,也不能因为某一帧没看到就立刻删除对象。它需要用当前内部状态生成预期,再用新观测去校验这个预期;只有当差异超过可解释范围时,才以受控方式更新信念。换句话说,自洽性解决的不是“存什么”,而是“如何在噪声、缺观测和世界变化中持续相信、怀疑或修正某个状态”。
容器推理是一个最简单但很有代表性的例子。用户把钥匙放进抽屉后,抽屉关闭,系统看不到钥匙。一个没有自洽性的系统可能会说“钥匙消失了”;一个有空间记忆的系统应该说:“根据上次观测,钥匙在抽屉里。当前看不到它是预期结果,因为抽屉关闭。只有当抽屉打开后仍然看不到,才应显著降低这个信念,并推断它可能已被取走。”
跨会话重定位也是同一个结构。用户第二天回到房间,系统需要区分三类情况:自己定位漂了、物体真的移动了、环境结构发生了变化。这已经超出单帧感知,进入新观测与历史状态之间的自洽性检验。类似地,机器记忆智能(Machine Memory Intelligence, M2I)框架也从工程角度把表征、学习与推理组织为闭环,强调结构化记忆层对于持续学习和协作推理的必要性 [66]。
因此,简约性和自洽性共同定义了空间记忆的底线:前者避免系统被原始数据淹没,后者避免系统被噪声和漂移带偏。缺少简约性,系统会变成昂贵的视频仓库;缺少自洽性,系统会变成永远自信、永远容易被单次观测误导的状态机。
4.4 世界模型视角:M 层与空间记忆的关系
还有一个与三层架构高度相关、但容易被误读的概念,就是 世界模型(World Model)。最近,这个概念有点泛滥,似乎在很短的时间之内,AI圈里冒出一大堆做世界模型的:视频生成、机器人、自动驾驶、游戏开发、AR/VR、Agent仿真/训练等等,只要和“世界”沾点边,就都可以是世界模型。我们这里不打算卷入围绕这个概念的种种争议。Genie 这类生成式交互环境和“从词语到世界”的空间智能论述,确实把长时一致性和物理世界状态维护推到了前台 [14, 16];但为了避免概念过度膨胀,我们仍然返璞归真到 Ha 与 Schmidhuber 在 2018 年提出的经典架构来勾勒它和空间记忆的关系。它最有启发性的地方并不只是“生成未来”,而是明确把智能体拆成了三个互相配合的部分:Vision(V)、Memory(M)和 Controller(C)[73]。
在这个结构中,V 负责把高维视觉输入压缩为低维 latent code;M 负责根据当前 latent code、动作和历史 hidden state 预测未来 latent state;C 则基于 V 与 M 提供的表示选择动作。换句话说,V 处理“我现在看到了什么”,M 处理“从过去到现在发生了什么、接下来可能发生什么”,C 处理“我接下来该做什么”。
从功能位置看,世界模型中的 M 层与本文所说的空间记忆有明显对应关系:它位于感知和控制之间,承担跨时间状态维护与未来预测的角色。没有 M,系统只能基于当前观测做反应;有了 M,系统才开始拥有某种“内部世界状态”,可以在观测缺失、环境随机和动作后果不确定的情况下进行预测。
但二者不能简单等同。原始世界模型架构中的 M 层是一个隐式的 latent dynamics model:它压缩历史信息,并预测下一个 latent code。它并不显式维护对象身份、容器关系、证据来源、置信度衰减,也不支持“钥匙上次在哪里”“为什么认为它还在那里”这类可解释查询。因此,更准确的说法是:M 层是空间记忆的早期抽象形态;而本文讨论的空间记忆,是对 M 层的结构化、对象化、可查询、可解释和可校准扩展,让它“现出原形”。
这个区分很重要。世界模型的关键不只是生成未来画面,而是在感知与行动之间维护一个可用于预测和决策的内部状态。对物理世界中的智能系统来说,这个内部状态不能只是一串不可解释的隐向量。它必须逐步承载对象、关系、时间、证据和不确定性。也正是在这个意义上,空间记忆可以被看作世界模型中 M 层在空间智能任务中的工程化落地方法。
4.5 小结:骨架、纪律与参照
第 4 节的核心结论可以压缩为三句话。
第一,认知科学中的“地标—路线—认知地图”并不是对“感知—认知—记忆”的逐项证明,而是提供了一条经验骨架:空间能力需要从局部锚点、可执行路径,逐步组织成可推理的空间结构。第二,简约性与自洽性提供了运行纪律:认知层必须把高维感知压缩成低维、结构化、可操作的状态;记忆层必须在噪声、遮挡、漂移和缺观测中维护可校准的信念。第三,世界模型中的 M 层提供了现代机器学习架构中的参照:它提示我们,智能系统需要在感知与行动之间维护内部状态;但真正面向物理世界的空间记忆,必须把这个状态进一步对象化、结构化、证据化和可查询化。
接下来的 §5 讨论具体技术路线、主流方法与评测问题,都围绕这两个问题展开:系统是否真的维护了一个结构化的世界状态?这个状态是否能够跨时间更新、接受查询、校准不确定性,并回溯到证据?
5. 技术路线、主流方法与评测
有了第 4 节的三层架构,接下来讨论技术路线时就不能只问“模型效果好不好”,而要问两个更具体的问题:第一,它是否把感知、认知与记忆的功能分工处理清楚;第二,它是否真的维护了一个简约、自洽、可查询、可校准、可追溯的世界状态。
按这个标准来看,当前路线大致可以分为两类:一类试图用全隐式端到端模型吸收空间能力;另一类则采用神经符号混合方式,用神经模型处理感知,用结构化状态承接认知与记忆。前者有开放词汇和端到端优化优势,但在证据链、在线更新和不确定性校准上存在结构性短板;后者更复杂,却更接近本文所说的空间记忆。
本节讨论三个问题:第一,构建空间记忆到底有哪几类技术路线;第二,为什么 NeRF / 3DGS 这类高保真三维表示不能直接等同于空间智能;第三,现有评测为什么仍然没有真正测到“跨会话、可校准、可追溯的空间记忆”。
5.1 两大范式:全隐式端到端 vs. 神经符号混合
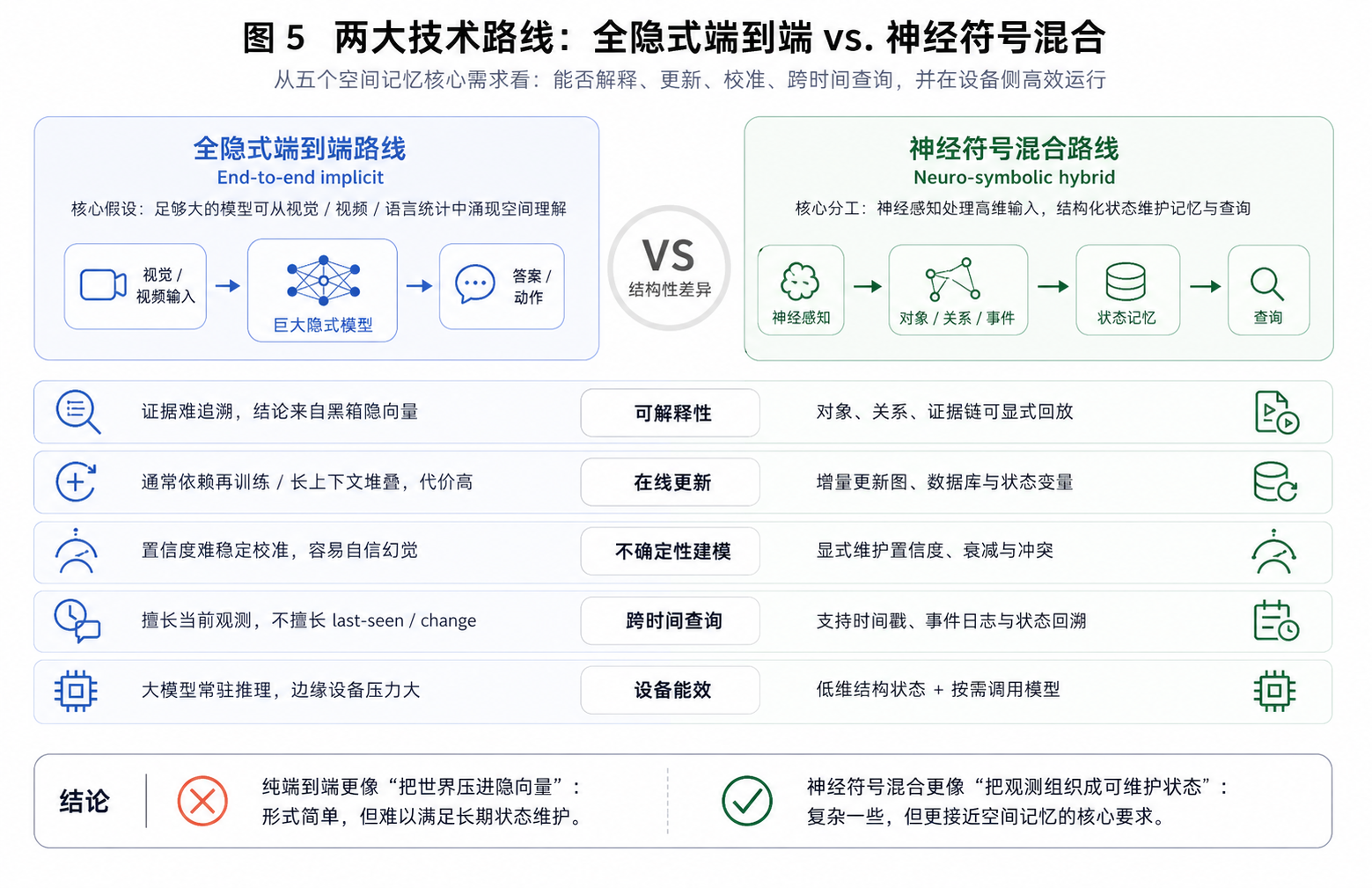
第一条是全隐式端到端路线。它相信只要模型足够大、数据足够多,空间理解能力就可以从视觉、视频和语言训练中自然涌现。这条路线有明显优势:系统形式简单,端到端优化方便,开放词汇能力强,也已经在图像描述、视频理解、三维重建辅助推理等任务上取得了可观进展。近期的 Spatial-MLLM、3DThinker、G²VLM、Think3D 等工作,也都在试图把几何信息重新引入 VLM 的推理过程:有的通过双编码器分离语义与三维结构特征,有的在潜空间中生成 3D token,有的通过三维工具调用让模型显式操作点云或视角 [19, 50, 51, 64]。
但这些进展也反向说明了一个事实:纯语言/视觉统计量不足以支撑稳定的空间推理,几何结构必须以某种方式进入系统。 更重要的是,这些方法多数仍然解决的是“当前观测下如何推理得更好”,而不是“跨天、跨会话如何维护一个可更新的世界状态”。对空间记忆而言,全隐式路线面临三个结构性困难:证据难追溯、在线更新代价高、不确定性难以稳定校准。模型可以说“钥匙在抽屉里”,但它通常无法可靠指向“我为什么相信它在那里、这条信念最后一次被什么观测支持、现在置信度应当下降到多少”。
第二条是神经符号混合路线。它的基本分工是:用神经模型处理感知侧的高维、连续、开放词汇输入;用结构化表示维护认知和记忆侧的低维、可组合、可查询状态。神经符号路线的基本出发点在于感知适合神经网络,而长期状态维护、证据链、不确定性和查询则更适合图、数据库、概率模型和符号接口。
这条路线可以组织为一条从底层到高层的工程链路:SLAM / metric mapping 提供几何一致性;object-level / semantic mapping 叠加对象语义;Dynamic Scene Graph 用图结构表达对象、地点、层级、关系和事件;概率知识图谱进一步加入置信度、衰减和冲突处理;开放词汇检索则为自然语言查询提供接口。Kimera [9]、Hydra [10]、Pandora [65]、SceneLLM [42]、RieMind [32] 等工作从不同侧面说明,这条路线虽然系统复杂、调试困难,但更接近空间记忆对“可解释、可更新、可查询、可校准”的要求。
因此,神经符号混合路线并不是在端到端模型不够强时采取的临时折中,而是更接近空间智能问题本身的结构:感知层需要神经网络处理高维、连续、开放词汇输入;认知层需要结构化表示压缩对象、地点、关系和约束;记忆层则需要概率更新、证据链和查询接口来维护跨时间信念。正是在这个意义上,神经符号混合路线目前最贴近第 4 节提出的“感知—认知—记忆”三层架构。
我们的推断是:未来真正可落地的空间记忆系统,很可能不会是纯端到端,也不会是纯符号系统,而是一个分层混合结构:底层保证几何与感知,中层维护对象和关系,高层提供查询、推理、证据与不确定性。
5.2 被误解的“颜值选手”:NeRF 与 3DGS 不等于空间智能
NeRF 和 3D Gaussian Splatting(3DGS) 近年来非常受关注,原因很容易理解:它们的视觉效果好,能够从照片或视频中生成高保真的新视角渲染,在虚拟制作、三维重建、文化遗产数字化等领域有实际价值。
但近两年我们频频听到把3DGS和空间智能关联到一起,甚至混为一谈划上等号的说法。作为空间信息科学与技术的长期从业者,我们每每看到这种结论,都禁不住对这种误读露出一丝苦笑。从空间记忆角度看,必须区分两件事:高保真三维可视化 与 可持续维护的世界状态。NeRF/3DGS 的核心目标是重建和渲染已知场景,而空间记忆要解决的是对象身份、空间关系、时间变化、遮挡信念、证据链和不确定性。前者回答“这个场景从另一个角度看起来像什么”,后者回答“这个对象是什么、上次在哪里、现在是否还在那里、为什么我这么认为”。
NeRF/3DGS 可以是空间记忆系统中的一种用于可视化目的的旁路表征,但远不能直接等同于空间智能。它们通常缺少对象级语义、长期状态更新和信念校准能力,仅仅是一种用于观赏的三维视觉艺术形式。这并不是说 NeRF 和 3DGS 没有价值——它们是多种空间表征中的一种,在其擅长的领域(高保真可视化、新视角合成)有不可替代的优势。需要避免的,只是把它们的“好看”误读为空间智能的全部。有趣的是,也的确有在 3DGS 之上叠加空间记忆能力的尝试。GSMem [40] 等工作把 3DGS 用作持久空间记忆载体,并在其上叠加对象级场景图和语义检索层。而有趣的点恰恰在于:它在证明 3DGS 的高保真重放能力有价值的同时也说明,3DGS 本身不够,必须叠加结构化语义层、对象层和查询层,才真正接近空间记忆。
5.3 核心工程挑战:从 Demo 到可用系统
拥有美丽皮囊的 Spatial AI demos 隔三岔五就会出现,已经不是稀奇事物。它们很容易给人一种“问题已经解决”的印象。但一旦把系统放到跨天、跨会话、可追溯的真实使用场景,一系列挑战随之而来。
挑战 1:跨时间身份一致性。 真实世界中没有天然的对象 UUID。相似物体、遮挡、光照变化、视角变化都会导致 identity switch。一旦系统把 A 错认成 B,后续关系更新、变化摘要和因果推断都会被连锁污染。
挑战 2:隐藏状态与容器推理。 “把钥匙放进抽屉”意味着钥匙暂时不可见,但不意味着它不存在。系统必须知道“看不到”不等于“不在”,并能随时间合理衰减信念。
挑战 3:重定位与漂移区分。 长期系统要区分两类非常相似的现象:是传感器/坐标系漂移了,还是物理世界真的变了?如果不能区分,系统会把自身误差当成外部变化,或把真实变化误判为定位误差。
挑战 4:间歇感知与长时空窗。 真实场景中通常不会全天候连续感知。设备会关机,用户会离开,传感器会被遮挡。系统需要在连续跟踪模式和长时间空窗后的 re-entry 模式之间切换,并在证据不足时诚实表达不确定。
挑战 5:证据保留与隐私最小化的张力。 可信系统需要证据,隐私友好系统又不能无限保存原始视频。空间记忆系统必须在稀疏关键帧、局部裁剪、哈希摘要、事件日志和用户可控删除之间找到合理平衡。
这些挑战说明,空间记忆无法通过“再加一个向量数据库”解决;它是一个涉及感知、图结构、概率更新、隐私工程和交互设计的系统问题。
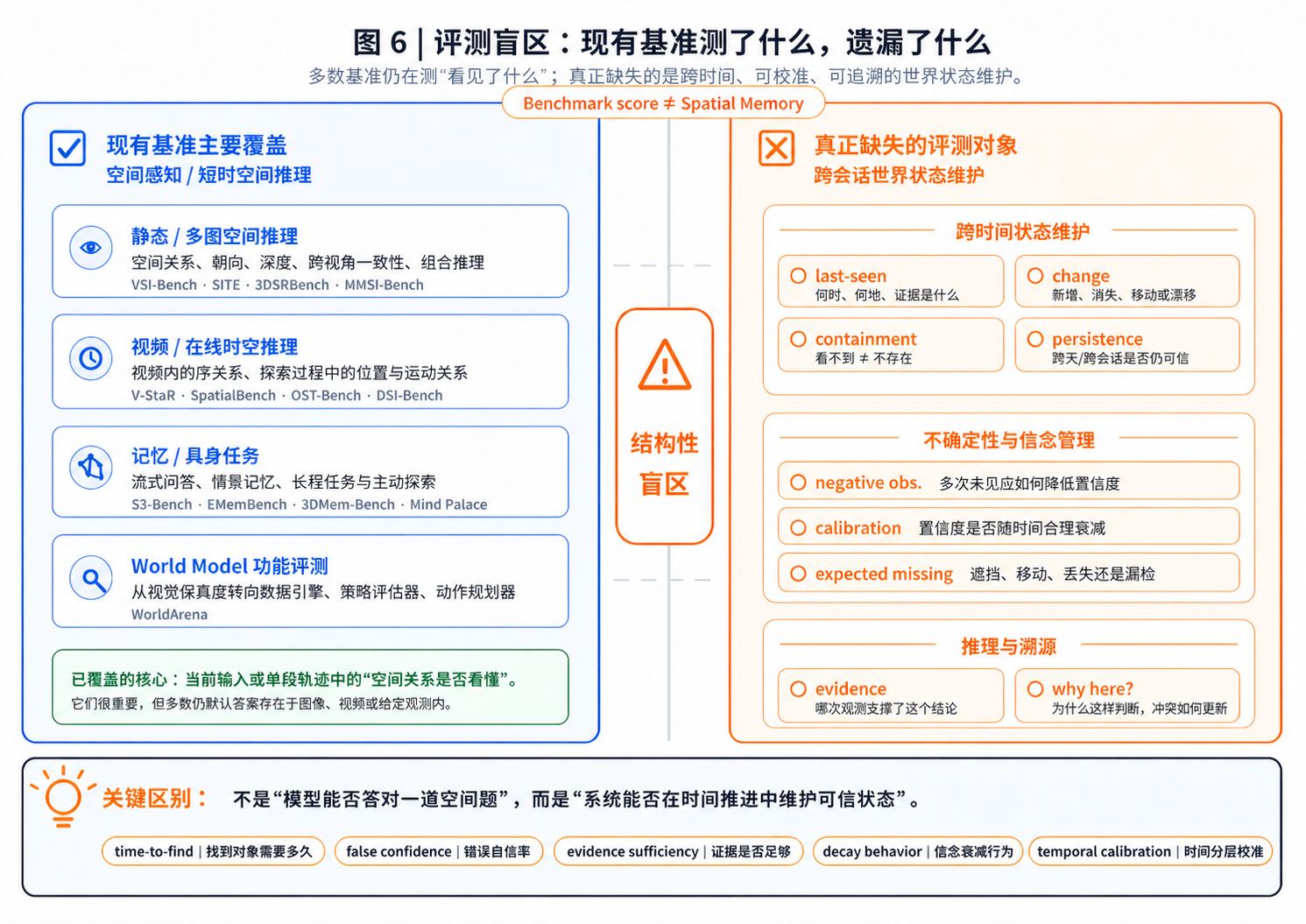
5.4 评测:现有基准测到了什么,又漏掉了什么
评测决定了研究社区在优化什么。在空间智能领域,2024–2026 年出现了大量有价值的基准,但它们大多仍在测“能否看懂当前或给定视频中的空间关系”,而不是“能否跨时间维护一个可信的世界状态”。
我们这里把现有评测粗略分为四类:
| 类型 | 代表基准 | 主要测什么 | 对空间记忆的盲区 |
|---|---|---|---|
| 静态/多图空间推理 | VSI-Bench [12], SITE [22], 3DSRBench [24], MMSI-Bench [20], OmniSpatial [63], HiSpatial [52], SpaCE-10 [55] | 空间关系、朝向、深度、多视角一致性、组合推理 | 通常不测长期状态维护、信念衰减、跨会话一致性 |
| 视频/在线时空推理 | V-STaR [25], SpatialBench [26], Spatial4D-Bench [27], OST-Bench [28], DSI-Bench [44] | 视频内时序关系、在线探索、运动中的空间关系 | 多数仍是单次连续轨迹或视频内工作记忆,不等于跨天持久记忆 |
| 记忆/具身任务 | S3-Bench [39], EMemBench [41], 3DMem-Bench [46], Mind Palace [49] | 流式问答、情景记忆、长程具身任务 | 开始接近问题核心,但仍较少覆盖负观测、跨会话状态、证据链和时间分层校准 |
| World Model 功能评测 | WorldArena [80] | Embodied world model 的视频质量、数据引擎、策略评估器、动作规划器等功能效用 | 开始从“视觉保真度”转向“下游功能”,但仍不直接测试对象级、跨会话、可查询的空间记忆 |
这些重要的基准测试工作已经清楚显示,当前模型在空间推理、主动探索和长时记忆任务上距离人类水平仍有明显差距。例如 VSI-Bench [12]、MMSI-Bench [20]、OST-Bench [28]、Theory of Space [31] 等都从不同角度揭示了“感知强 ≠ 空间认知强”的结构性问题。
更宽的元基准与专项评测也在给出相似信号:SIBench 从多数据集视角显示模型在理解与规划层面系统性欠缺,SPACE-EVAL、SpatialGenEval、MultihopSpatial 和 EscherVerse 分别从经典空间推理、生成侧空间约束、多跳组合推理与目的性空间推理角度暴露类似短板 [43, 30, 45, 47, 54]。而从机制层面看,有研究把空间推理拆成关系组合、表征变换和有状态空间更新等计算原语,进一步说明“更新已有空间信念”正是当前模型最薄弱的部分之一 [56]。
最近出现的 WorldArena [80] 值得单独列出。它不是严格意义上的空间记忆基准,而是面向 embodied world models 的统一评测框架:一方面用 16 个指标从视觉质量、运动质量、内容一致性、物理合理性、3D 准确性和可控性等维度评估生成视频;另一方面又把世界模型放进下游任务中,考察它能否作为 synthetic data engine、policy evaluator 和 action planner 服务于具身决策。它的关键发现与本文主线非常契合:高视觉质量并不必然转化为强具身任务能力。这说明评测不能只看模型“生成得像不像”,还必须看它维护的内部状态是否真的能支持行动。换句话说,WorldArena 虽然还没有直接测试跨会话空间记忆、负观测推理和证据链,但它把世界模型评测从“感知保真度”推向“功能效用”,因此是连接 §4.4 的世界模型讨论与本节评测盲区诊断的一个重要新基准。
但从本文关心的空间记忆角度看,真正的盲区仍然存在:现有基准很少测试跨会话的持久性世界状态维护。 典型问题如:三天前看到的钥匙是否仍可能在厨房?连续三次全房间扫描没有发现某物时,置信度应该如何下降?如果一个物体“应该存在但当前不可见”,系统应如何区分遮挡、移动、丢失和感知漏检?这些问题无法简单转化为传统 VQA,因为答案并不总在当前图像或完整视频里,而在一组随时间演化的信念状态中。
这也是 absent-state detection 和 negative observation 特别重要的原因。“没有看到”本身也是一种证据。对于一个已经有历史信念的系统,多次未检测到某物,应当逐步降低“它仍在这里”的概率;而对于一个没有历史信念的系统,同样的未检测可能几乎不提供信息。这个区别正是空间记忆和普通感知系统的分界之一。
Belief Scene Graphs、unobserved object detection 与 World Scene Graph Generation 等方向从不同角度说明,空间系统不仅要表示已经观测到的对象,也要表示“应该存在但暂时不可见”的对象及其不确定性 [35, 36, 37, 38]。
在我们正在构建的空间记忆能力实验中,一些早期结果显示加入贝叶斯置信度校准和负观测推理后,缺失检测能力相比纯感知基线有明显提升。它的方法论含义在于:空间记忆评测不能只问模型答得对不对,还要问它是否知道自己为什么这么答、证据是否足够、置信度是否随时间合理变化。
因此,空间记忆的评测至少应包含以下任务级指标:time-to-find、correction cost、false confidence rate、evidence sufficiency、forgetting / decay behavior,以及按时间分层的校准误差。传统 ECE 把不同时间跨度的样本混在一起,会掩盖“刚观测过”和“三天没观测过”之间的根本差异。空间记忆真正需要的是 temporal-stratified calibration:随着距上次观测时间增长,系统的置信度是否仍然可信?这一点也可以从天气预报和时间序列预测中的时效分层校准、context-driven distribution shift 研究中得到旁证:校准质量本来就可能随时间跨度和上下文状态发生系统性变化 [33, 34]。
最后还要警惕 Goodhart 定律。当 benchmark 变成目标,高分就可能来自捷径利用而不是真实能力提升。已有工作显示,一些空间基准可能被词袋或数据集捷径部分攻破 [29]。因此,在早期原型阶段,benchmark 分数应被视为参照,而不是终点。更值得信任的评测应基于证据可回溯的问答回放:系统给出的每个答案,都必须能指回时间戳、观测来源和不确定性来源。
6. 我们的判断与阶段性进展
前面几节已经把问题铺开:空间记忆不会在一个漂亮 demo 之后自然附带;智能系统要进入物理世界,必须认真处理这层状态维护能力。到这里,我们简要介绍一下黎曼慕尼黑团队在过去两年围绕这个问题进行思考与实践的三条线索。
6.1 持续评估空间智能:先把能力边界看清楚
第一条线索,是持续、系统地评估大模型的空间智能水平。
自 2022 年 11 月以来,我们一直在观察不同类型大模型在路线认知、空间关系、尺度转换和跨视角理解等任务上的表现。后来形成的 TurnBack 工作 [21],只是其中一个较为具体的切片:它把“反向路线理解”这个看似日常的任务,转化为一个可以比较、可以复现、可以暴露模型结构性短板的测试对象。
这类工作的价值,主要在于帮助我们分清几件经常被混在一起的能力:模型是否只是记住了语言模式?是否真的理解了路线结构?是否能在空间方向反转、尺度变化和路径重组时保持一致?如果这些问题没有被仔细测量,“空间智能”就很容易变成一个过于宽泛、也过于乐观的标签。
因此,我们对 benchmark 的态度很克制:它更像显微镜,用来观察当前模型究竟在哪些空间任务上失效,失效是否稳定,背后是否指向更深层的表征问题。
6.2 坚持显式表征:让空间结构进入认知模块
第二条线索,是坚持以显式表征的方式构建空间认知模块。
空间不是普通语义标签的集合。对象有位置,位置之间有拓扑,场景有层级,关系会随时间变化,遮挡与缺失本身也携带信息。把这些结构全部压进隐向量,然后期待模型自然学会长期维护世界状态,风险很高,也很难解释。
这也是我们重视神经符号路线的原因。神经模型适合处理高维、开放、噪声丰富的感知输入;显式结构则适合维护对象、关系、事件、证据与约束。RieMind [32] 这类工作从几何 grounding 和显式 3D scene graph 出发,说明当大模型被接入一个可操作、可检查的空间结构时,空间推理会变得更稳,也更容易被诊断。
对我们而言,显式表征并非怀旧的符号主义,也不意味着否定端到端模型。它更像一种实用主义的工程化方法:既然物理世界本身具有对象、关系、时间和约束,就不应把这些结构全部交给黑箱去猜。空间记忆要维护的正是这些结构在时间中的延续。
6.3 补齐空间记忆评测缺口:从“答对空间题”到“维护世界状态”
第三条线索,是试图补齐空间记忆本身的评测缺口。
现有空间智能基准已经非常有价值,但大多数仍然围绕“能否看懂当前图像、视频或给定轨迹中的空间关系”展开。它们能暴露模型在深度、方向、跨视角一致性和组合推理上的问题,却较少直接测试一个更核心的能力:系统是否能跨时间维护一个可信的世界状态。
空间记忆需要测的问题更接近这种形态:三天前看到的物体现在还可能在原处吗?多次未观测到某个对象时,置信度应如何下降?一个对象不可见时,系统应区分遮挡、移动、丢失还是感知漏检吗?当答案给出后,它能否指回证据、时间戳和不确定性来源?
这些问题不能简单归入传统 VQA,也不能只靠单次空间推理题覆盖。它们要求 benchmark 把时间、证据、负观测、置信度衰减和跨会话一致性纳入评测。我们正在撰写的这篇关于空间记忆的文章,正是在尝试把这个 gap 说清楚:空间记忆评测的核心问题,是系统能否在数月以上的时间跨度中维护、修正并解释自己的世界状态,而不只是上下文长度。
6.4 小结
所以,我们目前的工作并不急于宣称已经解决空间记忆。更准确地说,我们在做三件相互衔接的事:持续评估大模型的空间智能边界 [21];坚持把显式空间结构引入认知模块 [32];并尝试建立面向空间记忆本身的评测问题。
这三件事共同指向一个朴素判断:智能系统要进入物理世界,光会看见或者多模态感知还不够。它必须学会带着证据、不确定性和时间意识去维护世界状态。真正困难的地方,也许恰恰就在这里。
7. 从洞穴到世界
智能系统真正走向物理世界,并不是从“看见”开始的,而是从“记住世界曾经怎样、现在为何如此”开始的。
没有空间记忆,视觉只是不断闪过的影像;语言只是关于世界的描述;推理也常常悬浮在没有锚点的符号之上。只有当系统能够在时间中维持对象、位置、变化、证据与不确定性,所谓“世界”才不再只是输入流里的片段,而成为一个可以被持续理解和修正的对象。
这也是柏拉图“洞穴寓言”在今天仍然有力的原因。
7.1 洞穴隐喻:影子不是世界
柏拉图在《理想国》第七卷中写下著名的“洞穴寓言”:被锁在洞穴中的囚徒只能看见墙上的影子,于是误以为影子就是世界本身 [1]。这个隐喻放到今天的 AI 系统上,依然很有解释力。
大型视觉语言模型能够识别图像、描述视频、预测下一帧,甚至生成逼真的三维场景。它们在“影子”层面已经非常强大:像素、token、embedding、latent frame 都可以被看作世界投射到模型输入空间中的影子。但只会处理影子,并不等于理解世界。一个系统可以非常擅长描述一张图,却仍然不知道同一个物体是否在十分钟后仍然存在;可以生成一段连贯视频,却仍然不能解释某个对象为什么应该还在抽屉里;可以回答一个空间关系问题,却无法指出证据来自哪一次观测。
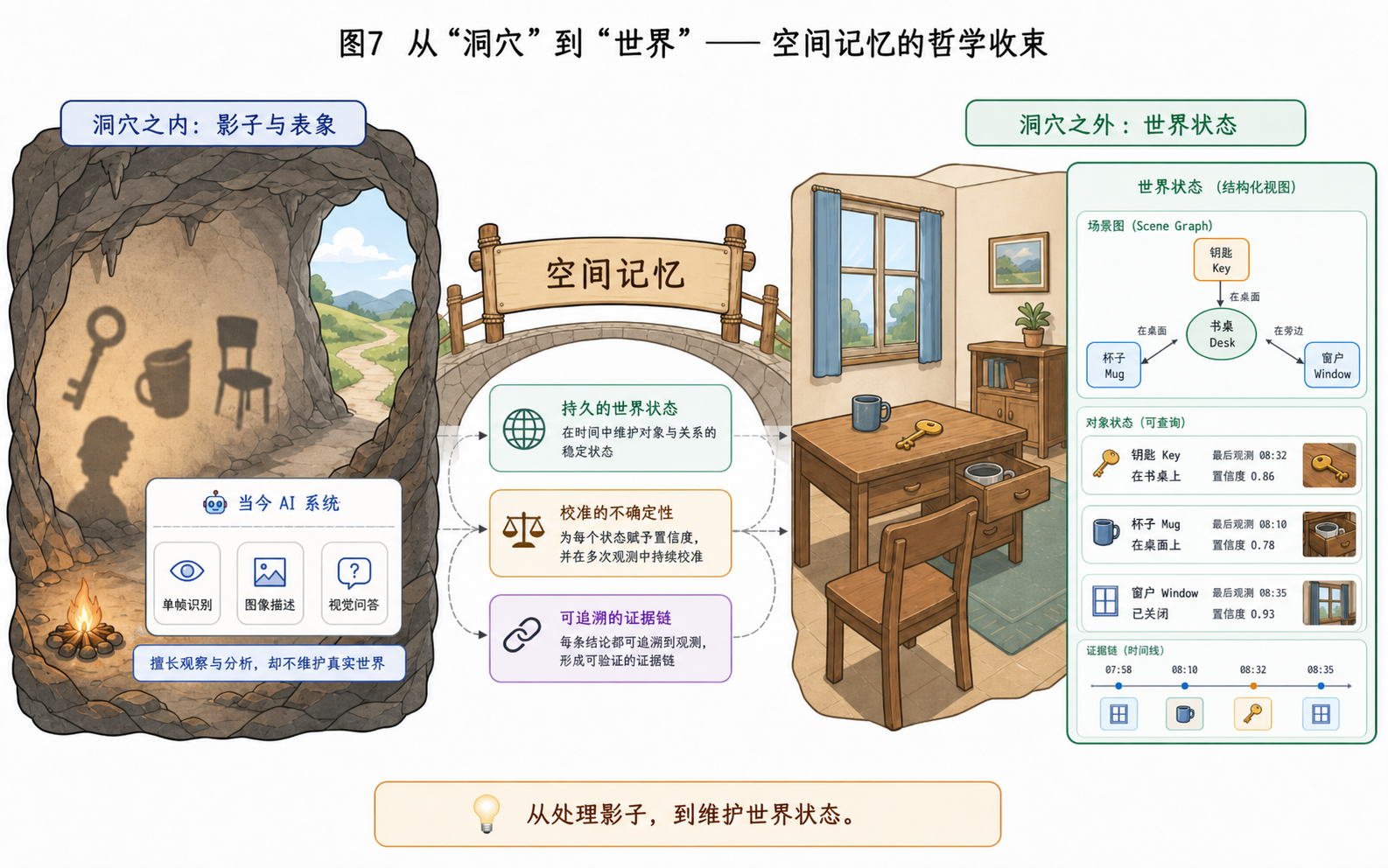
因此,空间记忆的意义并不是让 AI 系统“看得更多”,而是让它开始维护一个关于世界的内部状态:什么东西存在过、在哪里出现过、后来是否移动、当前判断有多可靠、证据是什么。这一步不是从影子直接跳到真理,而是从被动处理投影,转向主动维护一个可更新、可校准、可审计的时空状态模型。
7.2 物理世界需要不同的本体论
如果借用康德的语言,空间和时间是我们认知的先验形式 [2]。本文当然不是要把一个工程系统等同于人类的先验直观,而是希望传递“空间记忆是一种工程化的时空组织框架”这种观念。它让系统不只是接收感官输入,而是把输入组织成能够跨时间延续的世界状态。
这也解释了为什么从“词语世界”走向“物理世界”并不是一次平滑迁移。词语世界主要依赖语义约定和上下文一致性;物理世界则受到对象连续性、空间关系、遮挡、运动、因果和时间不可逆性的约束。一个杯子无论被如何命名,都不能同时既在桌上又在柜子里;一个行人被车辆遮挡,并不意味着他从世界中消失;一把钥匙放进抽屉后,即便短时间不可见,也仍然应当作为一个带置信度的信念被维护。
在这个意义上,空间记忆可以被理解为物理世界的最小本体论接口。它至少要处理三件事:
- 对象恒等性:同一个对象跨时间仍然是同一个对象,而不是每次观测中的一团新像素。
- 空间关系与隐藏状态:系统要区分“看不到”和“不存在”,并维护 on / in / near / behind 等关系。
- 变化、证据与不确定性:系统要知道状态何时改变、为什么改变、判断依据是什么,以及自己有多不确定。
这些能力听起来朴素,却正是当前许多空间智能系统尚未触及的部分。
7.3 仍然开放的问题
把空间记忆看作物理世界的认知底座,并不意味着问题已经解决。相反,它只是把问题边界画得更清楚。接下来仍有很多关键问题悬而未决:跨模态信息到底应在什么层级融合?不确定性的时间衰减应遵循什么数学形式?隐私最小化与证据可追溯之间如何平衡?什么样的空间记忆对家庭机器人、自动驾驶、XR 分别算“足够好”?跨设备、跨平台、跨尺度的空间状态又该如何统一?
还有一个本体论边界也需要坦诚面对:对象中心表征天然适合杯子、钥匙、椅子、车辆这类具有稳定身份的实体,却不天然适合液体、烟雾、火焰、阴影、柔性物体等更连续或更事件化的现象。对于这些对象,系统可能需要容器化表示、状态标签、事件节点或物质/现象本体,而不能简单套用普通 ObjectInstance 模型。承认这些边界,比声称一个统一框架可以包打天下更可信。
7.4 结语:从影子回到世界状态
柏拉图的洞穴寓言最后指向的是从影子走向真实世界。对 AI 系统来说,这个过程不会因为模型更大、视频更清晰、生成结果更逼真就自动完成。真正关键的中间步骤,是建立对世界状态的稳定、诚实、可信的表示。
这就是空间记忆在本文中的位置:它不是终点,也不是全部智能;但它是从“会描述世界的影子”走向“能维护世界的状态”时,绕不过去的一座桥。
世界不是提示词里的一段文字;而空间记忆是把“词语”变成“世界状态”的那座桥。
8. 参考文献与延伸阅读
-
Plato. The Republic. Book VII: Allegory of the Cave. (Original: ~380 BC). Numerous translations available; foundational text for understanding representation vs. reality in cognition.
-
Immanuel Kant. Critique of Pure Reason (1781/1787). Space and time as a priori forms of intuition; philosophical foundation for understanding spatiotemporal cognition. https://en.wikipedia.org/wiki/Critique_of_Pure_Reason
-
Tolman, E. C. (1948). Cognitive Maps in Rats and Men. Psychological Review, 55(4), 189–208. https://doi.org/10.1037/h0061626
-
O’Keefe, J. & Dostrovsky, J. (1971). The hippocampus as a spatial map. Preliminary evidence from unit activity in the freely-moving rat. Brain Research, 34(1), 171–175. https://doi.org/10.1016/0006-8993(71)90358-1
-
Hafting, T., Fyhn, M., Molden, S., Moser, M.-B. & Moser, E. I. (2005). Microstructure of a spatial map in the entorhinal cortex. Nature, 436(7052), 801–806. https://doi.org/10.1038/nature03721
-
Nobel Prize (2014). The Nobel Prize in Physiology or Medicine 2014. Awarded for discoveries of cells that constitute a positioning system in the brain. https://www.nobelprize.org/prizes/medicine/2014/press-release/
-
Peer, M., Brunec, I. K., Newcombe, N. S. & Epstein, R. A. (2021). Structuring knowledge with cognitive maps and cognitive graphs. Trends in Cognitive Sciences, 25(1), 37–54. https://doi.org/10.1016/j.tics.2020.10.004
-
Ekstrom, A. D. & Hill, P. F. (2023). Spatial navigation and memory: A review of the similarities and differences relevant to brain models and age. Neuron, 111(7), 1037–1049. https://doi.org/10.1016/j.neuron.2023.03.001
-
Rosinol et al. (2021). Kimera: from SLAM to Spatial Perception with 3D Dynamic Scene Graphs. https://arxiv.org/abs/2101.06894
-
Hughes et al. (2022). Hydra: A Real-time Spatial Perception System for 3D Scene Graph Construction and Optimization. https://arxiv.org/abs/2201.13360
-
Zheng, J. & Meister, M. (2025). The unbearable slowness of being: Why do we live at 10 bits/s? Neuron, 113(2), 192–204. https://doi.org/10.1016/j.neuron.2024.11.008
-
Yang, J., Yang, S., Gupta, A. W., Han, R., Fei-Fei, L. & Xie, S. (2025). Thinking in Space: How Multimodal Large Language Models See, Remember, and Recall Spaces. VSI-Bench; CVPR 2025. https://arxiv.org/abs/2412.14171
-
Gorlo, N., Schmid, L. & Carlone, L. (2025). Describe Anything Anywhere At Any Moment (DAAAM). Real-time 4D scene graph construction with open-vocabulary semantic annotations as spatio-temporal memory for embodied agents. https://arxiv.org/abs/2512.00565
-
Bruce et al. (2024). Genie: Generative Interactive Environments. Foundational work on world models with spatiotemporal consistency. https://arxiv.org/abs/2402.15391
-
Yang et al. (2025). Cambrian-S: Towards Spatial Supersensing in Video. Advanced spatiotemporal video understanding. https://arxiv.org/abs/2511.04670
-
Li, Fei-Fei (2024). From Words to Worlds: Spatial Intelligence is AI’s Next Frontier. World Labs perspective on spatial intelligence. https://drfeifei.substack.com/p/from-words-to-worlds-spatial-intelligence
-
Wang et al. (2024). Is A Picture Worth A Thousand Words? Delving Into Spatial Reasoning for Vision Language Models. SpatialEval benchmark; NeurIPS 2024. Demonstrates that competitive VLMs can fall below random guessing on spatial tasks. https://arxiv.org/abs/2406.14852
-
Cai et al. (2025). Scaling Spatial Intelligence with Multimodal Foundation Models. Systematic study on scaling laws for spatial intelligence; finds diminishing returns of naive data scaling. https://arxiv.org/abs/2511.13719
-
Wu et al. (2025). Spatial-MLLM: Boosting MLLM Capabilities in Visual-based Spatial Intelligence. Dual-encoder architecture separating semantic and 3D structural features for improved spatial reasoning from 2D inputs. https://arxiv.org/abs/2505.23747
-
Yang, S. et al. (2026). MMSI-Bench: A Benchmark for Multi-Image Spatial Intelligence. ICLR 2026. Addresses limitations of single-frame evaluation; proposes multi-image spatial reasoning tasks that require cross-view consistency. https://arxiv.org/abs/2505.23764
-
Luo et al. (2025). TurnBack: A Geospatial Route Cognition Benchmark for Large Language Models through Reverse Route. EMNLP 2025. Systematic evaluation of LLMs on spatial route cognition; identifies structural barriers in current LLM spatial representations. https://arxiv.org/abs/2509.18173
-
Wang et al. (2025). SITE: towards Spatial Intelligence Thorough Evaluation. ICCV 2025. Comprehensive evaluation framework for spatial intelligence covering multiple dimensions beyond VSI-Bench. https://openaccess.thecvf.com/content/ICCV2025/html/Wang_SITE_towards_Spatial_Intelligence_Thorough_Evaluation_ICCV_2025_paper.html
-
Yang, A. et al. (2025). Evaluating and enhancing spatial cognition abilities of large language models. International Journal of Geographical Information Science, 39(9), 2009–2044. Systematic evaluation of LLMs across classic spatial cognition dimensions (landmark recognition, path integration, layout understanding, perspective-taking); finds significant cross-dimensional asymmetry with some dimensions falling below random baselines. https://doi.org/10.1080/13658816.2025.2490701
-
Ma, W. et al. (2025). 3DSRBench: A Comprehensive 3D Spatial Reasoning Benchmark. ICCV 2025. 2,772 manually annotated QA pairs across 12 spatial reasoning subtypes with FlipEval innovation; reveals models lag humans significantly on height, location, and orientation reasoning. https://arxiv.org/abs/2412.07825
-
Cheng et al. (2025). V-STaR: Benchmarking Video-LLMs on Video Spatio-Temporal Reasoning. Video-based what/when/where reasoning with chain-of-thought evaluation; best model accuracy ~40%. https://arxiv.org/abs/2503.11495
-
Xu et al. (2025). SpatialBench: Benchmarking Multimodal Large Language Models for Spatial Cognition. 1,347 QA from 50 egocentric videos spanning 15 tasks and 5 cognitive levels. https://arxiv.org/abs/2511.21471
-
Wang, P., Liu, Y., Wu, G. et al. (2026). Spatial4D-Bench: A Versatile 4D Spatial Intelligence Benchmark. ~40,000 QA, 18 tasks, 6 cognitive categories. First benchmark to name “spatial memory” as a task, though limited to within-video working memory (tracking occluded objects). https://arxiv.org/abs/2601.00092
-
Lin et al. (2025). OST-Bench: Evaluating the Capabilities of MLLMs in Online Spatio-temporal Scene Understanding. NeurIPS 2025. 1.4K scenes, 10K QA. Key finding: MLLM accuracy degrades systematically as exploration horizon extends and memory load increases. https://arxiv.org/abs/2507.07984
-
Udandarao, V., Karthik, S., Nath, S. S., Hochlehnert, A., Bethge, M. & Prabhu, A. (2025). Solving Spatial Supersensing Without Spatial Supersensing. Critical analysis showing NoSense bag-of-words baseline achieves 95% on VSR; Cambrian-S evaluation collapses under simple repetition. Demonstrates widespread shortcut exploitation in spatial benchmarks. https://arxiv.org/abs/2511.16655
-
Wang, S. et al. (2026). SPACE-EVAL: Evaluating Spatial Reasoning in Large Language Models. ICLR 2026. 1,139 image-question pairs across Spatial Reasoning, Commonsense Knowledge, and Environment Interaction. Best overall accuracy: GPT-5 at 56.37%; highest spatial reasoning accuracy merely 42.25%. Human performance 84.18% vs. model best 56.37%. https://openreview.net/pdf/8e05a376c95a5e781207a327baeb1e3a0dc4d2de.pdf
-
Zhang et al. (2026). Theory of Space: Can Foundation Models Construct Spatial Beliefs through Active Exploration? Stanford / Fei-Fei Li team. Evaluates active spatial belief construction; reveals Active-Passive Gap (GPT-5.2 drops from 57.1% to 46.0%), Belief Inertia (~20% overwrite rate), and systematic belief instability over exploration. https://arxiv.org/abs/2602.07055
-
Ropero et al. (2026). RieMind: Geometry-Grounded Spatial Agent for Scene Understanding. Agentic neuro-symbolic framework grounding LLM in explicit 3D scene graph with geometric tools; achieves up to 16% improvement over prior SOTA on VSI-Bench static split, 33-50% over base VLM agentic variants. https://arxiv.org/abs/2603.15386
-
Kurki et al. (2025). Probability calibration for precipitation nowcasting. Introduces Expected Thresholded Calibration Error (ETCE) across precipitation thresholds with selective scaling + lead time encoding, reducing calibration error by 23.5%. Confirms temporal conditioning matters for calibration in weather forecasting. https://arxiv.org/abs/2510.00594
-
Chen et al. (2024). Calibration of Time-Series Forecasting: Detecting and Adapting Context-Driven Distribution Shift. KDD 2024. Introduces temporal segment-based calibration and residual-based CDS detector (Reconditionor); closest ML-domain precedent for temporal context-dependent calibration. https://arxiv.org/abs/2310.14838
-
Saucedo et al. (2024). Belief Scene Graphs: Expanding Partial Scenes with Objects through Computation of Expectation. ICRA 2024. Proposes predicting expected but unobserved objects in partial 3D scene graphs using graph-based learning (CECI model). https://arxiv.org/abs/2402.03840
-
Saucedo et al. (2025). Estimating Commonsense Scene Composition on Belief Scene Graphs. Extends Belief Scene Graphs with commonsense spatial distribution estimation using GCN and neuro-symbolic LLM-based spatial ontology. https://arxiv.org/abs/2505.02405
-
Bhattacharjee et al. (2025). Believing is Seeing: Unobserved Object Detection using Generative Models. CVPR 2025. Introduces unobserved object detection in 2D/2.5D/3D — predicting presence and location of nearby objects that are occluded or out of frame, using adapted diffusion and VLMs. Formalizes the task and proposes evaluation metrics. https://arxiv.org/abs/2410.05869
-
Peddi et al. (2026). Towards Spatio-Temporal World Scene Graph Generation from Monocular Videos. Formalizes World Scene Graph Generation (WSGG) — scene graphs encompassing ALL interacting objects, observed and unobserved. Proposes ActionGenome4D dataset and three methods: PWG (persistent world graph via feature buffer), MWAE (masked world auto-encoder for occlusion reasoning), 4DST (4D scene transformer with temporal attention). https://arxiv.org/abs/2603.13185
-
Wei, Y., Huang, W., Chen, Q., Hou, L. & Qi, X. (2026). S3-Bench: See, Remember, Explore: A Benchmark and Baselines for Streaming Spatial Reasoning. First benchmark for streaming spatial QA with temporal grounding and active exploration. 10K+ scenes, 26K+ trajectories. Queries are temporally grounded to specific timestamps and must be answered using only observations available up to that moment. Proposes AMF-VLM with memory folding (compressing long-horizon observations into compact structured memory) and active exploration. https://arxiv.org/abs/2603.23864
-
Lu, Y., Du, Y., Liu, D., Zhou, Y., Wang, C. & Yin, Y. (2026). GSMem: 3D Gaussian Splatting as Persistent Spatial Memory for Zero-Shot Embodied Exploration and Reasoning. Uses 3DGS as persistent spatial memory enabling “spatial recollection” — rendering photorealistic novel views from previously unoccupied viewpoints. Demonstrates that post-hoc re-observation from memory resolves initial observation misses that are irrecoverable in discrete scene graph or snapshot representations. https://arxiv.org/abs/2603.19137
-
Li, X. et al. (2026). EMemBench: Interactive Benchmarking of Episodic Memory for VLM Agents. Programmatic benchmark generating questions from each agent’s own trajectory. Covers single/multi-hop recall, induction, temporal, spatial, logical, and adversarial memory skills. Key finding: spatial reasoning is a persistent bottleneck across all tested agents, especially in visual settings. https://arxiv.org/abs/2601.16690
-
SceneLLM (Zhang et al., 2025). SceneLLM: Implicit Language Reasoning in LLM for Dynamic Scene Graph Generation. Pattern Recognition 2026. Uses LLM as scene analyzer with Video-to-Language mapping and Spatial Information Aggregation inspired by Chinese character structure. Achieves SOTA on ActionGenome benchmark for dynamic SGG. https://arxiv.org/abs/2412.11026
-
Yu et al. (2025). How Far are VLMs from Visual Spatial Intelligence? A Benchmark-Driven Perspective. SIBench: meta-benchmark spanning ~20 open-source spatial reasoning datasets across 23 task settings, categorized into perception/understanding/planning. Key finding: models show competence in basic perceptual tasks but consistently underperform in understanding and planning, with pronounced gap in numerical estimation, multi-view reasoning, temporal dynamics, and spatial imagination. https://arxiv.org/abs/2509.18905
-
Zhang et al. (2025). DSI-Bench: A Benchmark for Dynamic Spatial Intelligence. ~1,000 dynamic videos, 1,700+ manually annotated questions covering 9 decoupled motion patterns. Reveals models conflate observer and object motion, exhibit semantic biases, and fail at relative relationship inference in dynamic scenarios. https://arxiv.org/abs/2510.18873
-
Wang, Z., Hu, X., Wang, Y., Xiong, F., Zhang, M. & Chu, X. (2026). Everything in Its Place: Benchmarking Spatial Intelligence of Text-to-Image Models (SpatialGenEval). ICLR 2026. 1,230 information-dense prompts, 12,300 multi-choice QA across 10 spatial sub-domains. Evaluation of 23 SOTA T2I models reveals universal bottleneck in higher-order spatial reasoning (~60% accuracy ceiling). Complementary SpatialT2I dataset (15,400 pairs) yields consistent fine-tuning gains. https://arxiv.org/abs/2601.20354
-
Hu et al. (2025). 3DLLM-Mem: Long-Term Spatial-Temporal Memory for Embodied 3D Large Language Model. NeurIPS 2025. Dual-memory architecture (working memory + episodic memory) with cross-attention fusion module; introduces 3DMem-Bench (26,000+ trajectories, 2,892 embodied tasks). Achieves +16.5% over baselines on in-the-wild tasks; 27.8% success on hard tasks vs ~5% for baselines. https://arxiv.org/abs/2505.22657
-
MultihopSpatial (2026). MultihopSpatial: Multi-hop Compositional Spatial Reasoning Benchmark for Vision-Language Model. 4,500 manually annotated VQA pairs with 1- to 3-hop compositional spatial queries. Introduces Acc@50IoU metric requiring both answer selection and bounding box prediction. GPT-5.2-Thinking drops from 45.8% (standard MCQ) to 9.4% (grounded metric) on 3-hop queries, revealing that reasoning and localization capabilities remain largely decoupled in current VLMs. RL post-training on the corpus transfers to improved embodied VLA performance. https://arxiv.org/abs/2603.18892
-
Shi et al. (2025). MemoryVLA: Perceptual-Cognitive Memory in Vision-Language-Action Models for Robotic Manipulation. ICLR 2026. Cognition-Memory-Action framework with Perceptual-Cognitive Memory Bank storing low-level details and high-level semantics from historical trajectories. Working memory retrieves decision-relevant entries and adaptively fuses them with current tokens. 84.0% success on 12 real-world tasks (+26% on long-horizon temporal dependency tasks vs CogACT/π-0 baselines). Demonstrates that even fine-grained manipulation is non-Markovian and requires temporal memory. https://arxiv.org/abs/2508.19236
-
Ginting et al. (2025). Enter the Mind Palace: Reasoning and Planning for Long-term Active Embodied Question Answering. RSS 2025. Structures robot’s long-term observations as spatiotemporal world instances, each represented by hierarchical scene graphs linked across time. Enables targeted memory retrieval and guided navigation for answering temporally-grounded spatial questions. Demonstrates that long-term active EQA requires interleaving memory recall and active exploration. https://arxiv.org/abs/2507.12846
-
Chen et al. (2025). Think with 3D: Geometric Imagination Grounded Spatial Reasoning from Limited Views. CVPR 2026. First framework enabling 3D mental rotation during VLM reasoning without 3D prior input — generates compact latent 3D embeddings as tokens, emulating human mental rotation. Two-stage training: supervised alignment with 3D foundation model, then outcome-based optimization of reasoning trajectories. https://arxiv.org/abs/2510.18632
-
Hu et al. (2025). G²VLM: Geometry Grounded Vision Language Model with Unified 3D Reconstruction and Spatial Reasoning. CVPR 2026. Mixture-of-Transformer-Experts architecture with geometric and semantic perception experts sharing self-attention. Achieves competitive results on depth estimation, point estimation, camera pose estimation, AND spatial reasoning tasks within a single model. https://arxiv.org/abs/2511.21688
-
Liang et al. (2026). HiSpatial: Taming Hierarchical 3D Spatial Understanding in Vision-Language Models. CVPR 2026. Four-level progressive framework decomposing 3D spatial understanding from basic attributes (depth, distance) to complex multi-object compositional reasoning. Automated pipeline processing ~5M images with 45M+ object annotations. Confirms hierarchical performance degradation: models handle low-level spatial attributes but fail systematically at higher compositional levels. https://arxiv.org/abs/2603.25411
-
Lei et al. (2025). RoboMemory: A Brain-inspired Multi-memory Agentic Framework for Interactive Environmental Learning in Physical Embodied Systems. Brain-inspired framework unifying four memory subsystems (Spatial, Temporal, Episodic, Semantic) with parallelized updates and retrieval. Core innovations: dynamic spatial knowledge graph for consistent memory updates, closed-loop planner with critic module. On EmbodiedBench (Qwen2.5-VL-72B backbone): +26.5% average success rate over baseline, surpassing Claude-3.5-Sonnet. Real-world trials confirm cumulative learning across repeated tasks. https://arxiv.org/abs/2508.01415
-
Gu et al. (2026). EscherVerse: An Open World Benchmark and Dataset for Teleo-Spatial Intelligence with Physical-Dynamic and Intent-Driven Understanding. Introduces Teleo-Spatial Intelligence (TSI): unified evaluation of physical-dynamic reasoning (object permanence, state transitions, trajectory prediction) and intent-driven reasoning (connecting physical events to underlying human purposes). 11,328 real-world videos, 8,000-example benchmark, 35,963-example training set. Best proprietary model: 57.26% vs human mean 90.62%. https://arxiv.org/abs/2601.01547
-
Gong et al. (2025). SpaCE-10: A Comprehensive Benchmark for Multimodal Large Language Models in Compositional Spatial Intelligence. Defines 10 atomic spatial capabilities (object recognition, spatial localization, spatial relationship judgement, size comparison, counting, function knowledge, multi-view fusion, forward thinking, reverse reasoning, situated observation) and combines them into 8 compositional capabilities. 5,000+ QA pairs across 811 real indoor scenes from ScanNet++, ScanNet, 3RScan, and ARKitScenes. Key finding: counting (C5) is a universal bottleneck (max 38.8%), and compositional tasks integrating C7/C9/C10 drop 49–55%. https://arxiv.org/abs/2506.07966
-
An et al. (2026). From Human Cognition to Neural Activations: Probing the Computational Primitives of Spatial Reasoning in LLMs. Decomposes spatial reasoning into three computational primitives: relational composition, representational transformation, and stateful spatial updating. Probes LLMs via linear probing and causal interventions; reveals “mechanistic degeneracy” — similar behavioral performance arises from distinct internal pathways. Current LLMs exhibit limited and context-dependent spatial representations rather than robust general-purpose spatial reasoning. https://arxiv.org/abs/2603.26323
-
Ruan et al. (2025). From Reactive to Cognitive: Brain-Inspired Spatial Intelligence for Embodied Agents (BSC-Nav). Tsinghua / Beihang. Unified framework implementing the neuroscience “landmark → route → survey knowledge” hierarchy as an engineering system: landmark memory module encodes salient-cue-to-location associations, cognitive map module transforms egocentric trajectories into allocentric voxelized maps, working memory module dynamically retrieves and composes spatial representations aligned with semantic goals. Achieves SOTA across object-goal, open-vocabulary, and instance-level navigation, with strong generalization to instruction following, embodied QA, and mobile manipulation. https://arxiv.org/abs/2508.17198
-
Khangaonkar et al. (2026). Multimodal Language Models Cannot Spot Spatial Inconsistencies. Proposes a scalable method for generating spatially inconsistent image pairs from multi-view scenes. SOTA MLLMs significantly underperform human observers and exhibit substantial variability across scene attributes (object depth, lighting, physical plausibility). Different models fail on similar pairs but give divergent wrong answers, suggesting fragile and incomplete 3D understanding rather than robust spatial representations. https://arxiv.org/abs/2604.00799
-
He et al. (2025). Building Spatial World Models from Sparse Transitional Episodic Memories. ICLR 2026. Introduces the Episodic Spatial World Model (ESWM), a neuroscience-inspired framework that constructs spatial maps from sparse, disjoint episodic memories. The learned latent space geometry aligns with environment topology; independently stored and updateable episodic memories enable rapid adaptation to environmental changes. Enables near-optimal zero-shot exploration and navigation in novel continuous environments without task-specific training. https://arxiv.org/abs/2505.13696
-
Gwak et al. (2026). Cog3DMap: Multi-View Vision-Language Reasoning with 3D Cognitive Maps. KAIST. Recurrently constructs an explicit 3D memory from multi-view images where each token is grounded in 3D space with both semantic and geometric information. Feeding spatially structured 3D tokens into MLLM enables direct reasoning over spatial structure rather than implicit inference from flat visual tokens. Achieves state-of-the-art on multiple spatial reasoning benchmarks. https://arxiv.org/abs/2603.23023
-
Gao et al. (2026). Map2Thought: Explicit 3D Spatial Reasoning via Metric Cognitive Maps. Introduces Metric-CogMap (unified discrete grid + continuous metric-scale representation) and Cognitive Chain-of-Thought (deterministic geometric operations including vector operations, bounding-box distances, and occlusion-aware appearance cues). Achieves 59.9% accuracy using only half the supervision, closely matching the 60.9% full-data baseline. Demonstrates that explicit, interpretable geometric reasoning outperforms implicit spatial inference. https://arxiv.org/abs/2601.11442
-
Hippoformer (ICLR 2026). Hippoformer: Integrating Hippocampus-inspired Spatial Memory with Transformers. Proposes mm-TEM (meta-MLP Tolman-Eichenbaum Machine) as a scalable structural spatial memory module that produces grid-cell-like periodic spatial codes, and integrates it with Transformer working memory. The hybrid architecture outperforms pure Transformers on 2D and 3D spatial prediction and generalization tasks, demonstrating that hippocampal-inspired structured spatial encoding can be learned end-to-end within modern deep learning architectures. https://openreview.net/forum?id=hxwV5EubAw
-
Jia, M., Qi, Z., Zhang, S. et al. (2025). OmniSpatial: Towards Comprehensive Spatial Reasoning Benchmark for Vision Language Models. 50-subcategory spatial reasoning benchmark grounded in cognitive psychology (dynamic reasoning, complex spatial logic, spatial interaction, perspective-taking). 8,400 human-annotated QA pairs. SOTA VLMs 56.3% vs human 92.6%. PointGraph and SpatialCoT enhancements yield limited improvements, suggesting prompt engineering alone cannot compensate for missing spatial representations. https://arxiv.org/abs/2506.03135
-
Zhang et al. (2026). Think3D: Thinking with Space for Spatial Reasoning. Equips VLM agents with interactive 3D chain-of-thought reasoning via a suite of 3D manipulation tools (camera operations, view switching, point cloud interaction). Zero-shot plug-in for closed-source models (GPT-4.1, Gemini 2.5 Pro) yields +7.8% absolute gain on BLINK Multi-view, MindCube, and VSI-Bench. Think3D-RL (reinforcement learning for tool-use optimization) amplifies gains from +0.7% to +10.7% on Qwen3-VL-4B. https://arxiv.org/abs/2601.13029
-
Yu et al. (2026). Pandora: Articulated 3D Scene Graphs from Egocentric Vision. MIT-SPARK / Luca Carlone group. Extends the Hydra scene graph framework to include articulated object parts (drawers, cabinets, doors) by leveraging egocentric data from human-worn Aria glasses. Simple heuristics recover articulation models with quality comparable to SOTA; integration into 3D scene graphs enables robots to understand object-container relationships and perform concealed-item retrieval. Demonstrates human→robot knowledge transfer via structured spatial representations. https://arxiv.org/abs/2603.28732
-
Zheng et al. (2025). Machine Memory Intelligence: Inspired by Human Memory Mechanisms. Engineering (journal). Introduces the Machine Memory Intelligence (M2I) framework, mapping neural memory mechanisms (associative representation, replay-based continual learning, collaborative reasoning) to machine memory modules. Identifies three structural deficits in current LLMs — excessive data consumption, catastrophic forgetting, and black-box reasoning — as consequences of lacking structured memory. Proposes representation→learning→reasoning closed loop inspired by hippocampal consolidation. https://doi.org/10.1016/j.eng.2025.01.012
-
Allen, G. L. (Ed.) (2004). Human Spatial Memory: Remembering Where. Lawrence Erlbaum Associates. ISBN: 978-0-8058-4218-7. Comprehensive edited volume on the cognitive science of human spatial memory, covering encoding, retrieval, and individual differences.
-
Andersen, P., Morris, R. G. M., Amaral, D. G., Bliss, T. V. P., & O’Keefe, J. (Eds.) (2007). The Hippocampus Book. Oxford University Press. Authoritative reference on hippocampal structure, function, and role in spatial memory and navigation. https://doi.org/10.1093/acprof:oso/9780195100273.001.0001
-
Hebb, D. O. (1949). The Organization of Behavior: A Neuropsychological Theory. John Wiley & Sons. Foundational text proposing “cell assembly” and “phase sequence” theories for how neural circuits encode and organize experience, directly influencing spatial memory research.
-
Stachenfeld, K. L., Botvinick, M. M., & Gershman, S. J. (2017). The hippocampus as a predictive map. Nature Neuroscience, 20(11), 1643–1653. https://doi.org/10.1038/nn.4650
-
Mahadevan, S. & Maggioni, M. (2007). Proto-value Functions: A Laplacian Framework for Learning Representation and Control in Markov Decision Processes. Journal of Machine Learning Research, 8, 2169–2231. Canonical reference establishing graph Laplacian spectral decomposition as a framework for representation learning in state spaces. https://jmlr.csail.mit.edu/papers/v8/mahadevan07a.html
-
Sorscher, B., Mel, G. C., Ocko, S. A., Giocomo, L. M., & Ganguli, S. (2023). A unified theory for the computational and mechanistic origins of grid cells. Neuron, 111(1), 121–137.e13. https://doi.org/10.1016/j.neuron.2022.10.003
-
Ha, D. & Schmidhuber, J. (2018). World Models. arXiv:1803.10122. Classic V/M/C architecture: Vision compresses observations, Memory predicts future latent states, Controller selects actions from latent and memory states. https://arxiv.org/abs/1803.10122
-
Hu, X. et al. (2024). DrivingWorld: Constructing World Model for Autonomous Driving via Video GPT. Proposes a GPT-style autonomous-driving world model with spatial-temporal fusion mechanisms and next-state prediction for temporal coherence. https://arxiv.org/abs/2412.19505
-
Feng, T., Wang, W. & Yang, Y. (2025). A Survey of World Models for Autonomous Driving. Surveys autonomous-driving world models across future physical-world generation, behavior planning, and prediction-planning interaction. https://arxiv.org/abs/2501.11260
-
Poggenhans, F., Pauls, J.-H., Janosovits, J., Orf, S., Naumann, M., Kuhnt, F. & Mayr, M. (2018). Lanelet2: A high-definition map framework for the future of automated driving. Introduces an open-source lane-level/HAD map framework and argues that maps compensate for sensor limits, provide information about occluded or out-of-range regions, and transfer knowledge from previous journeys. https://www.mrt.kit.edu/z/publ/download/2018/Poggenhans2018Lanelet2.pdf
-
Mobileye. Road Experience Management™ (REM™). Describes a crowdsourced, continuously updated map built from Mobileye-equipped vehicles; emphasizes near-real-time updates, change detection, and a semantic layer of driving culture and traffic rules. https://www.mobileye.com/technology/rem/
-
Wirthmüller, F. et al. (2020). A Fleet Learning Architecture for Enhanced Behavior Predictions During Challenging External Conditions. Proposes a fleet-learning architecture in which vehicles collect challenging situations and backend updates improve motion prediction parameters over time. https://dbis.eprints.uni-ulm.de/2012/1/scci_wirth_2020_cr.pdf
-
Karnchanachari, N., Geromichalos, D., Tan, K. S., Li, N., Eriksen, C., Yaghoubi, S., Mehdipour, N., Bernasconi, G., Fong, W. K., Guo, Y., & Caesar, H. (2024). Towards learning-based planning: The nuPlan benchmark for real-world autonomous driving. ICRA 2024. Introduces the nuPlan real-world autonomous driving dataset and benchmark, with 1,282 hours of driving scenarios across four cities and closed-loop planning evaluation. https://arxiv.org/abs/2403.04133
-
Shang, Y., Li, Z., Ma, Y., Su, W., Jin, X. et al. (2026). WorldArena: A Unified Benchmark for Evaluating Perception and Functional Utility of Embodied World Models. Introduces a unified benchmark for embodied world models across video perception quality and downstream functional utility, including use as data engines, policy evaluators, and action planners; reveals a perception-functionality gap. https://arxiv.org/abs/2602.08971
-
Kahneman, D. (2011). Thinking, Fast and Slow. Farrar, Straus and Giroux. Introduces the widely used System 1 / System 2 distinction; here used only as a cognitive analogy for fast perceptual processing versus slower deliberative state maintenance.
-
Buchanan, S., Pai, D., Wang, P. & Ma, Y. (2026). Principles and Practice of Deep Representation Learning; or A Mathematical Theory of Memory. Version 2.0, open-source textbook. https://ma-lab-berkeley.github.io/deep-representation-learning-book/